PaddlePaddle-Y1Y2-Classification
- PaddlePaddle-Y1Y2-Classification
- 1. SE-ResNext
- (1)num_epochs = 50
- (1)num_epochs = 100
- 2. ResNet
- 3. NeverMoreNet
- 4. DNN
- 5. SoftMax回归
- 总结
PaddlePaddle-Y1Y2-Classification
1. SE-ResNext
(1)num_epochs = 50
最终2054张测试图像,正确率为99.707%,6张错误图像(只展示了4张)。
尝试分析误检图像,发现确实与常规有差异。
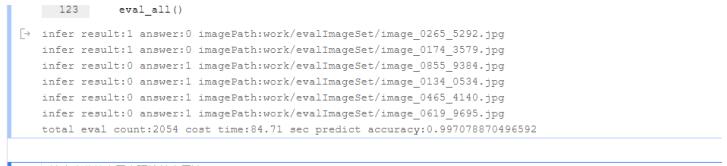

(1)num_epochs = 100

当训练轮数到100轮的时候,2054张测试图像,正确率为99.853%,3张错误图像。


以上为三张分类错误的图像。
当然也跑过99.95%只错一张这样的结果,可能只是运气好:

2. ResNet
SE-ResNext相比ResNet是增加了通道上的注意力机制,但是网络相对复杂,分析Y1Y2图像,原本就是灰度图像,所以通道与通道间的关系信息其实并不重要,所以尝试使用ResNet50网络。
我直接训练了100轮,结果如下:

正确率99.90%,错了两张图。但是速度明显快了挺多,2054张图只用了62s。合30ms一张,但是这前提都是使用的Tesla V100显卡,GPU预测的。所以速度方面我这里需要继续优化,看后文分解。
当然碰巧吧,我使用Resnet跑出来一个100%正确率的成绩。也是唯一的一次。

3. NeverMoreNet
自己写的一个最简单的CNN网络。其实里面的结果基本就是Lenet手写体那个网络结构,但毕竟是CNN,和普通的多层感知机还是不一样的。
这个网络结构比较简单,所以这里可以简单的讲一下:
其实就是 卷积->池化->卷积->池化->最后接个Fc全链接。但我自己在中间加了一些层,比如BN,比如正则化等。
可以看到这个CNN网络并不是很复杂。
同样我也训练了100轮,最终结论:


原以为效果并不会很好,没想到最终结果也非常不错,看来自己构造的这个小CNN还是可以的。2054张图只错了三张。而且预测时间是惊人的。2054张图只用了5s。每张图预测时间为:2.4ms。这样的网络部署到实际客户端,也许我们CPU就够了。这无疑是个利好消息。
4. DNN
在我理解,其实多层感知机就是DNN,具体含义和内容这里不再赘述。
我这里放了两个隐藏层,大小分别为128和64。
同样我也训练了100轮,最终结论:


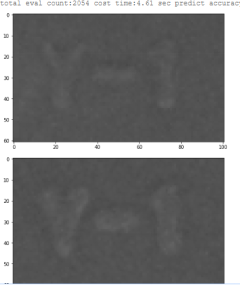




一共错了11张,但是预测速度更快,平均每张图2.2ms。
但是多层感知机我从训练端得知,这种方式存在不稳定性,但是结构简单,训练到100轮的时候才基本趋于稳定。

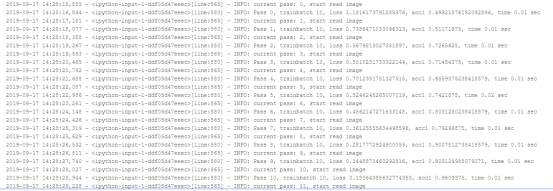
而在前几轮训练的时候效果并不好。但这也不失为一种解决方法,效果也可以接受。
5. SoftMax回归
如果我把网络再简化,简化到只有一层Fc全链接会怎样。同样训练100轮,我们看看最终效果:

居然这样也行!??时间更短了,每张图在Tesla V100GPU预测下,只需要1.6ms。
总结
我个人觉得,这个问题可能根本不需要CNN,但是相比之下,还是CNN效果更好!本文目的意在对CNN和DNN等网络效果进行简单评估,效果基本和预期一致!






