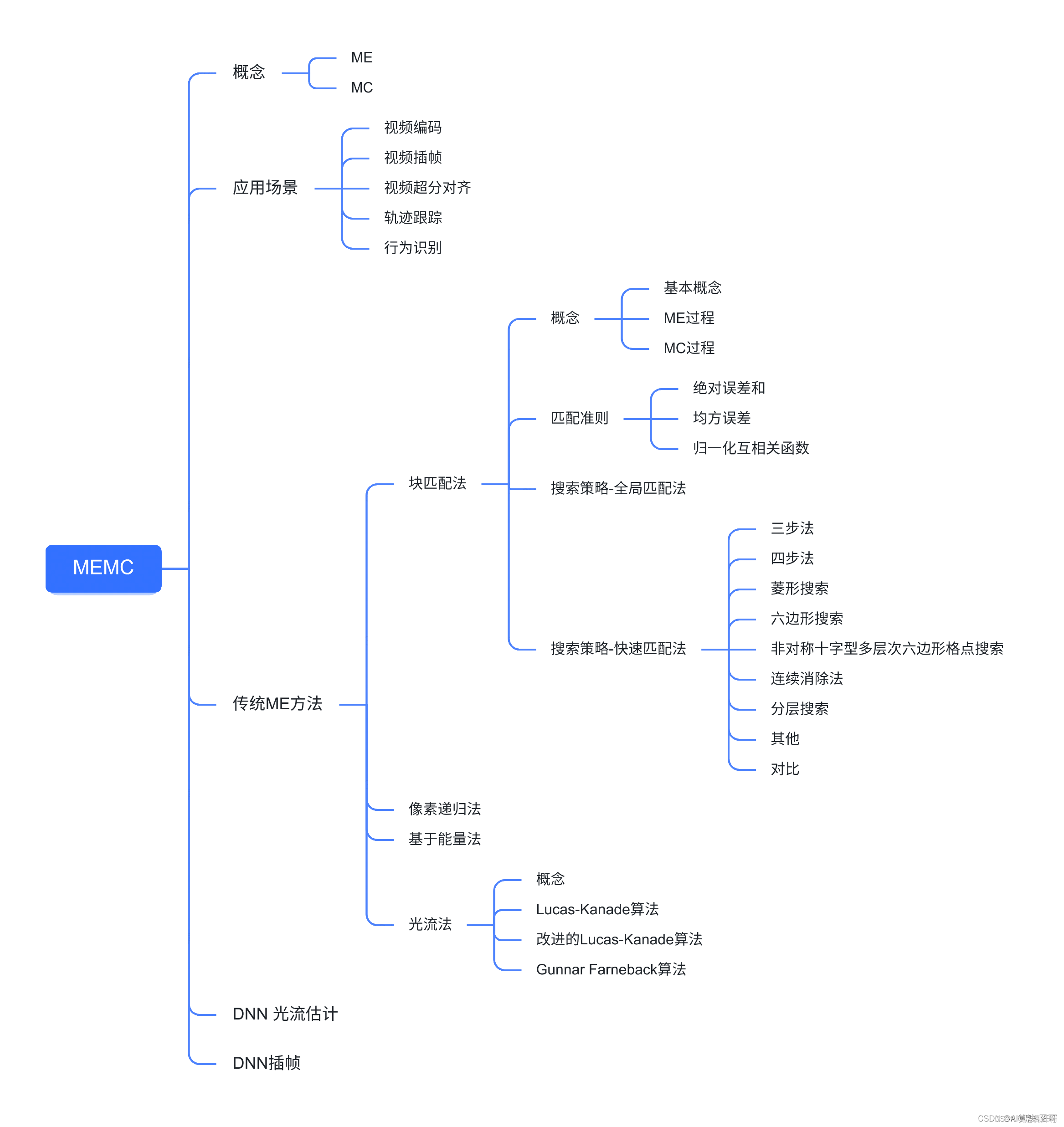
1.概念
1.1 ME
ME用来将获得相邻两帧图像中块或者像素的位移矢量
详见 https://zhuanlan.zhihu.com/p/100311043
1.2 MC
MC通过获得的运动矢量,对前一帧进行warp,获得新的帧。它是减少帧序列冗余信息的有效方法。
详见 https://zhuanlan.zhihu.com/p/336035647
2. 应用场景
2.1 视频编码
获得运动矢量及残差,然后压缩传输,之后恢复。
基于块的视频压缩代码可见: https://blog.csdn.net/q18421896/article/details/116998818
2.2 视频插帧
获得运动矢量后估计中间帧,与压缩不同,插帧需要对矢量处理到一半左右,不同方法具体操作不同。
24帧到60帧的插帧方式为单数后插一帧,双数后插两帧
30帧到60帧的插帧方式为每帧后插一帧
2.2.1 电影24帧为什么比游戏30帧看着流畅
电影帧可以完整记录一段时间内的光线信息
详见 https://www.igao7.com/news/201510/QMB9FrbTUNLvjpd8.html
2.2.2 插帧其他方法
Duplication、 Blend、Motion Interpolation
详见 https://www.cnblogs.com/TaigaCon/p/10612354.html
2.3 视频超分辨率重建
2.4 轨迹追踪
主要使用稀疏光流,详见下文LK算法
2.5 视频行为识别
https://blog.csdn.net/elaine_bao/article/details/80891173
3. 传统ME算法
由于MEMC中精准运动矢量的估计是至关重的,因此ME的研究相对较多。
3.1 块匹配 block-matching algorithm (BMA)
3.1.1 概念
应用场景
在H.264和MPEG中广泛采用,一般将RGB转为YCbCr通道,然后分别进行匹配。
基本思想
基本思想是将图像序列的每一帧分成许多互不重叠的宏块,并认为宏块内所有象素的位移量都相同,然后对每个宏块到参考帧某一给定特定搜索范围内根据一定的匹配准则找出与当前块最相似的块,即匹配块,匹配块与当前块的相对位移即为运动矢量。
缺点
在块之间引入的非连续性,通常称为块效应。
当高频分量较大时,会引起振铃效应。
3.1.2 匹配准则
- 绝对误差和(SAD, Sum of Absolute Difference)准则;
- 均方误差(MSE, Mean Square Error)准则
- 归一化互相关函数(NCCF, Normalized Cross Correlation Function)准则。
3.1.3 搜索策略-全局匹配
把搜索区域内所有的像素块逐个与当前宏块进行比较,查找具有最小匹配误差的一个像素块为匹配块
作用于视频压缩时MEMC matlab代码实现 https://github.com/liruidesysu/VideoCompression/blob/master/PzhenGuJi.m
3.1.4 搜索策略-快速匹配
该方法按照一定的数学规则进行匹配块的搜索。这一方法的好处是速度快,坏处是可能只能得到次最佳的匹配块。
3.1.4.1 三步法(Log 搜索法)
类似corase-to-fine,搜索窗口逐次减半,每次在上轮最优的基础上继续。
https://blog.csdn.net/weixin_45615071/article/details/105904300
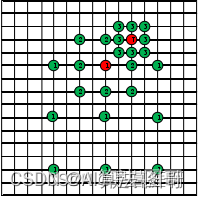
3.1.4.2 新三步法、精简三步法、四步法
详细查看 https://blog.csdn.net/u012745772/article/details/18798577
3.1.4.3 菱形搜索法(DIA)
又称钻石匹配法,按如下模板搜索,如果小于阈值停止,否则以最小点为中心继续搜索。
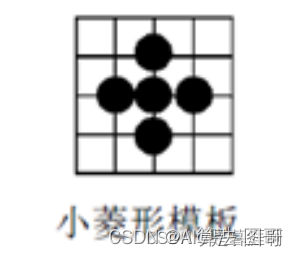
3.1.4.4 六边形搜索算法(HEX)
3.1.4.5 非对称十字型多层次六边形格点搜索算法(UMH)
该方法是编码最常用的方法。使用了多个模板逐次匹配。
上述3.1.4.3-3.1.4.5 三种搜索方法详见雷神博客 https://blog.csdn.net/leixiaohua1020/article/details/45936267
3.1.4.6 连续消除法(ESA、TESA)
是一种全搜索算法,它对搜索区域内的点进行光栅式搜索,逐一计算并比较。
3.1.4.6 分层搜索
为解决大位移问题,提出利用图像金字塔,先搜索小图像尺寸,然后逐层优化。
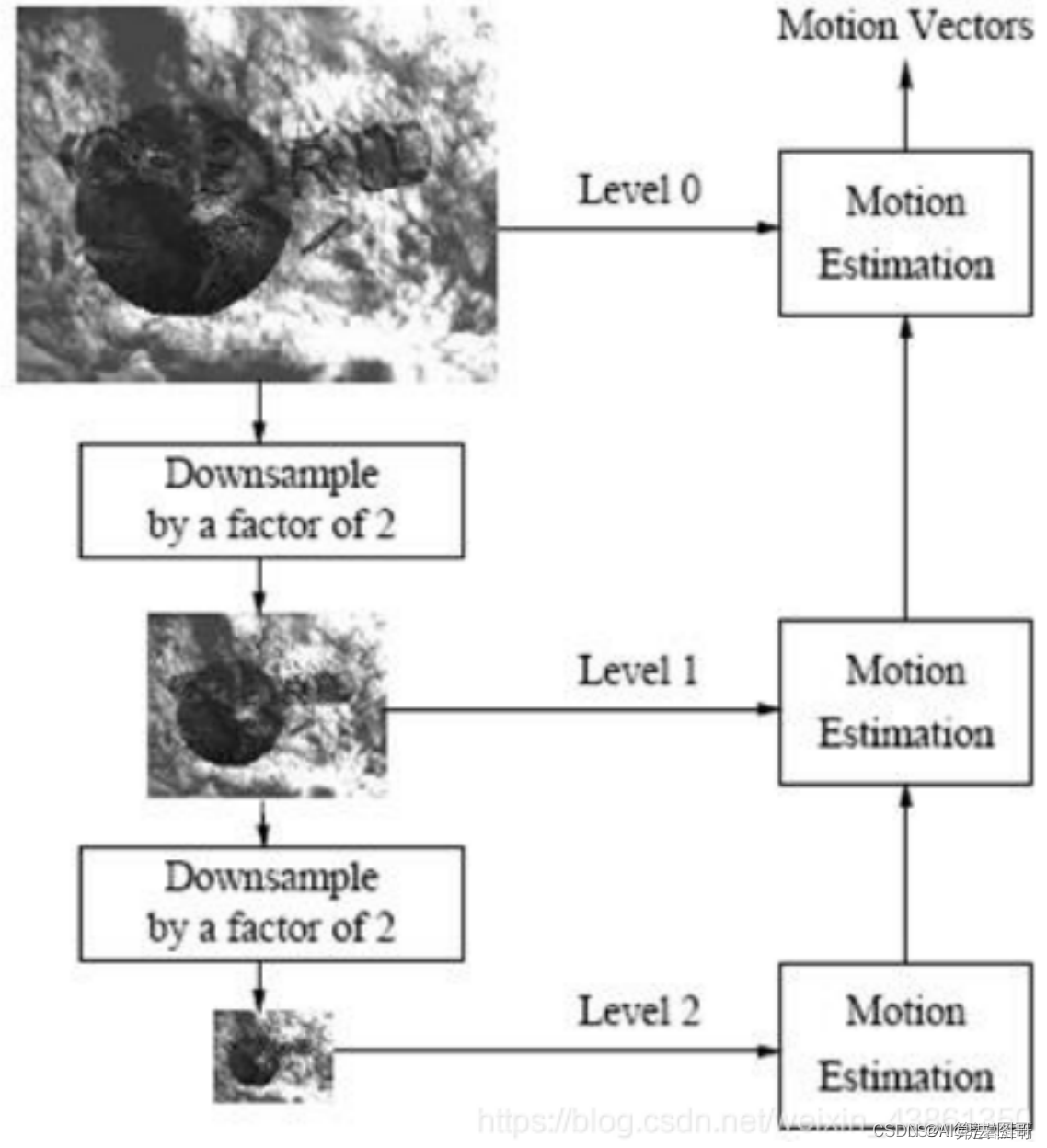
3.1.4.7 其他
主要从以下几个方面着手:
- 预测搜索起点
- 中止判别条件
- 搜索模板的选择
3.1.4.8 结果对比
采用了“Foreman”(运动剧烈)、“Carphone”(中等运动)、“Claire”(运动较小)几个视频作为实验素材,搜索范围为设置为16,实验的结果如下表所示。
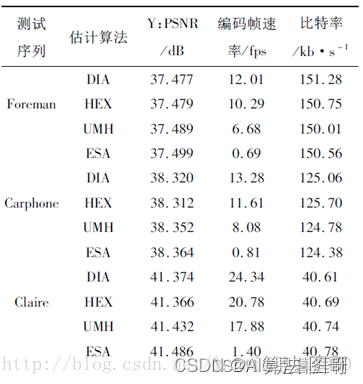
依旧来自雷神 https://blog.csdn.net/leixiaohua1020/article/details/45936267
3.2 像素递归 pel-recursive algorithm (PRA)
对每一个像素的位移进行估计,很耗时,一般不常用。
3.3 基于能量法(频率法)
基于能量的方法又称为基于频率的方法,在使用该类方法的过程中,要获得均匀流场的准确的速度估计,就必须对输入的图像进行时空滤波处理,即对时间和空间的整合,但是这样会降低光流的时间和空间分辨率。基于频率的方法往往会涉及大量的计算,另外,要进行可靠性评价也比较困难。
3.4 光流法
3.4.1 概念
光流、光流场、光流法一文讲清 https://blog.csdn.net/qq_41368247/article/details/82562165
光流–LK光流–基于金字塔分层的LK光流–中值流 https://blog.csdn.net/sgfmby1994/article/details/68489944
代码实现 https://zhuanlan.zhihu.com/p/69999853
3.4.2 Lucas-Kanade算法
是一种经典的稀疏光流估计算法,该算法为1981年由Lucas和Kanade两位科学家提出的。算法做出了三个假设
- 亮度恒定
- 时间持续性(微小移动)
- 空间一致性
三个基本假设中前两个是光流法的基本假设,第三个是LK算法特有的。
公式原理详见 https://zhuanlan.zhihu.com/p/105998058
当计算结果不可逆时,产生的孔径效应下文所示:https://zhuanlan.zhihu.com/p/74460341
3.4.3 改进的Lucas-Kanade算法
为了解决大位移问题,需要在多层图像缩放金字塔上求解,每一层的求解结果乘以2后加到下一层。
Opencv函数实现:
cv2.calcOpticalFlowPyrLK
经常搭配 cv2.goodFeaturesToTrack 函数提前检出关键点。
算法介绍详见 https://blog.csdn.net/u012554092/article/details/78128795
对视频进行估计代码可见 https://zhuanlan.zhihu.com/p/105998058
3.4.4 Gunnar Farneback算法
用于计算稠密光流,出自论文《Two-Frame Motion Estimation Based on PolynomialExpansion》
Opencv函数实现:
cv2.calcOpticalFlowFarneback
函数介绍详见 https://zhuanlan.zhihu.com/p/39644714
对应补偿一般搭配cv2.remap函数。
3.5 相位法
代码: https://github.com/owang/PhaseBasedInterpolation
论文: Phase-Based Frame Interpolation for Video [Meyer et al. CVPR 2015].
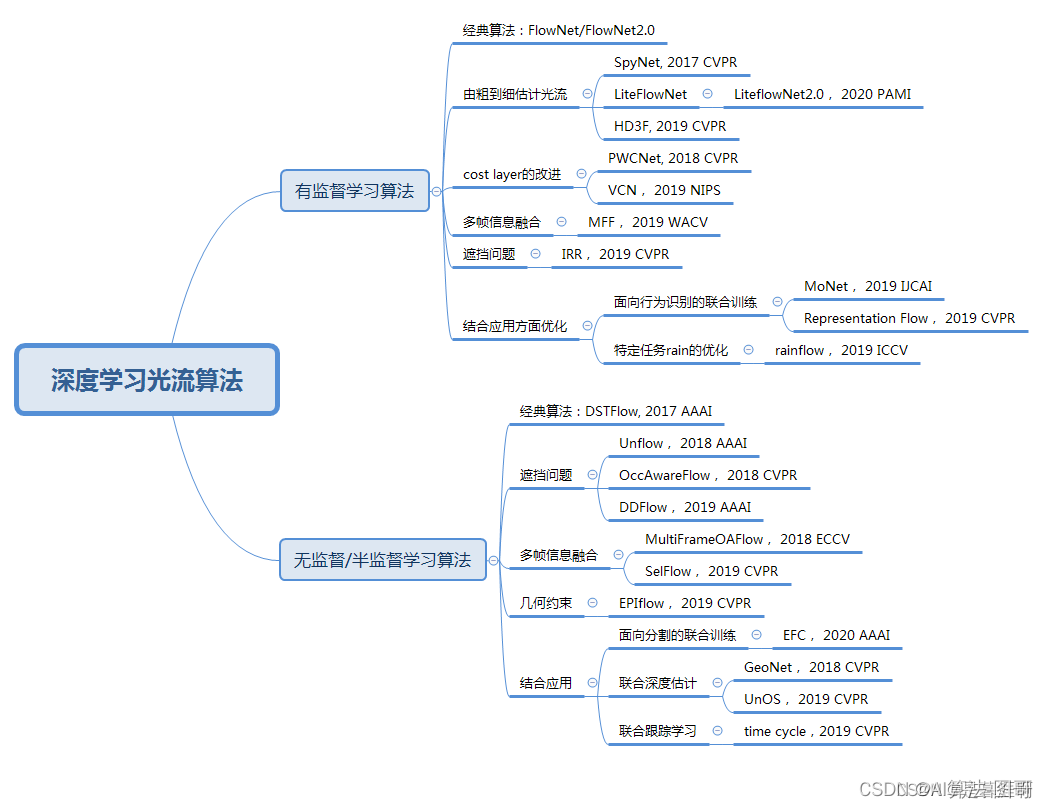
4. DNN光流估计
https://zhuanlan.zhihu.com/p/128672851
5 DNN插帧
专辑 https://string.quest/read/17354977
结果对比 https://zhuanlan.zhihu.com/p/362525023