先上效果图,效果是真不错呀!

 带大家复现这个过程
带大家复现这个过程
一、下载源码
代码下载地址:
链接:https://pan.baidu.com/s/1MkW7DOgNHD5h5sfXQ6L1HA
提取码:ynev
权重下载地址:
链接:https://pan.baidu.com/s/1lEt1t3KZVN7_k8ktPpnypA
提取码:q070
UAVid数据集下载地址:
链接:https://pan.baidu.com/s/1rAirhr1ZMsLm_815pv282A
提取码:zegk
二、租赁环境
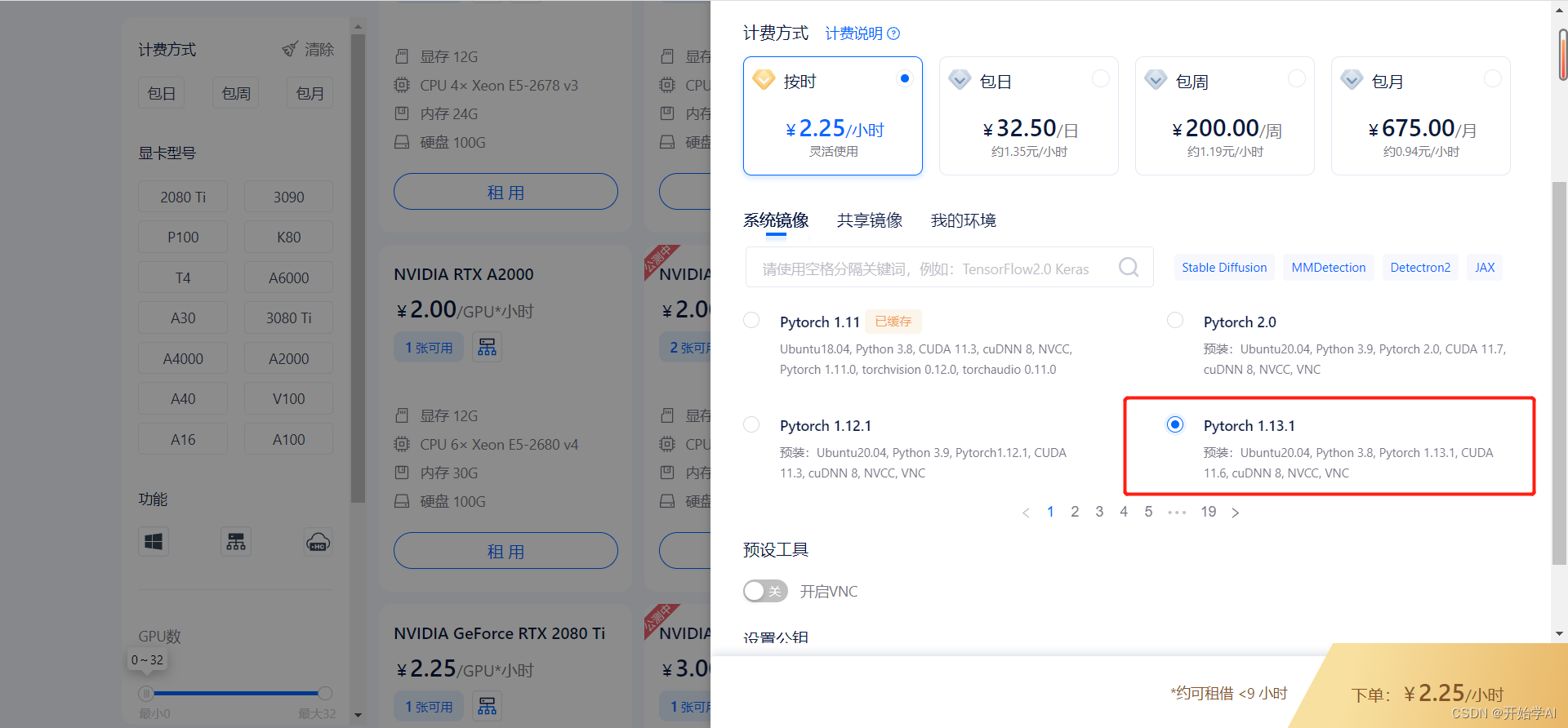
三、Vscode连接矩池云
教程:VS Code 远程连接矩池云机器教程 | 矩池云支持中心
四、上传数据
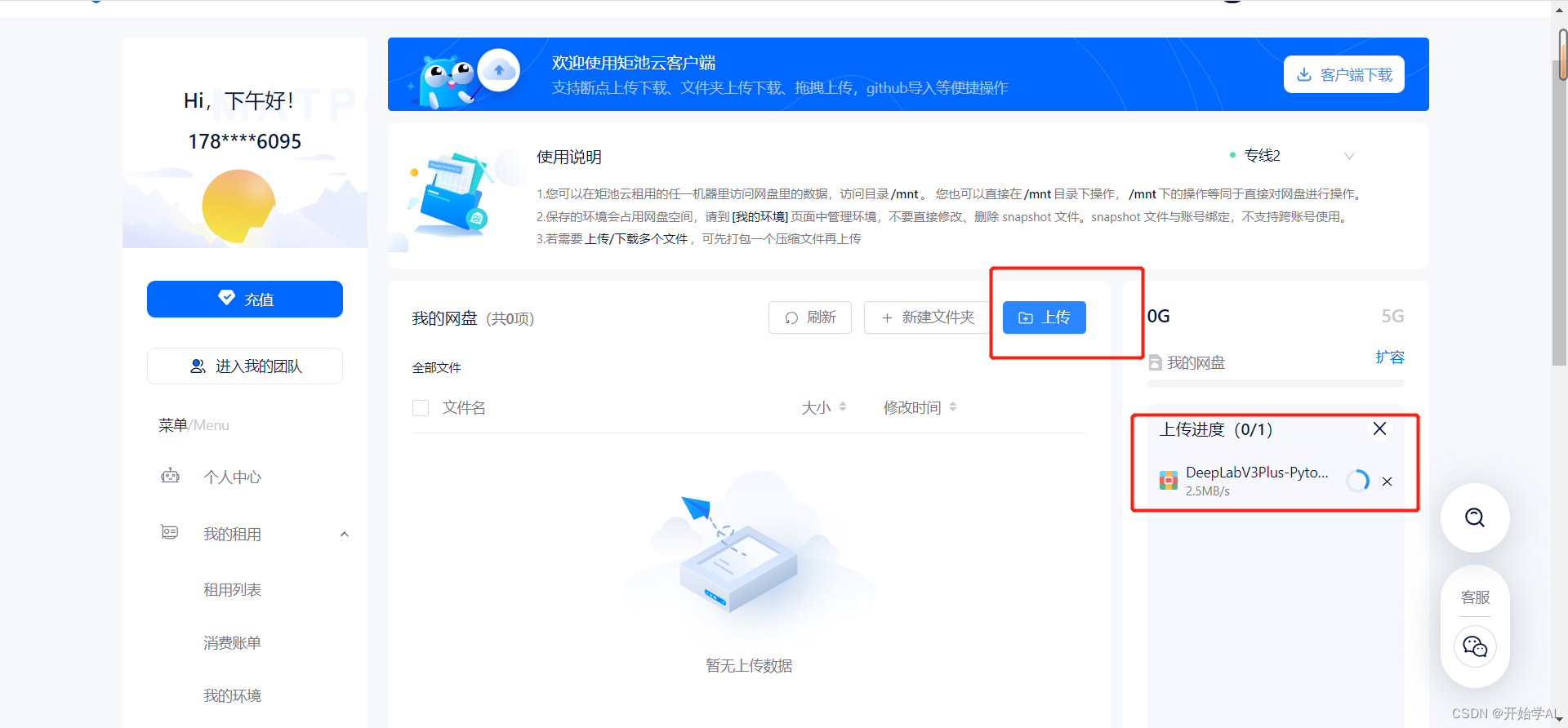
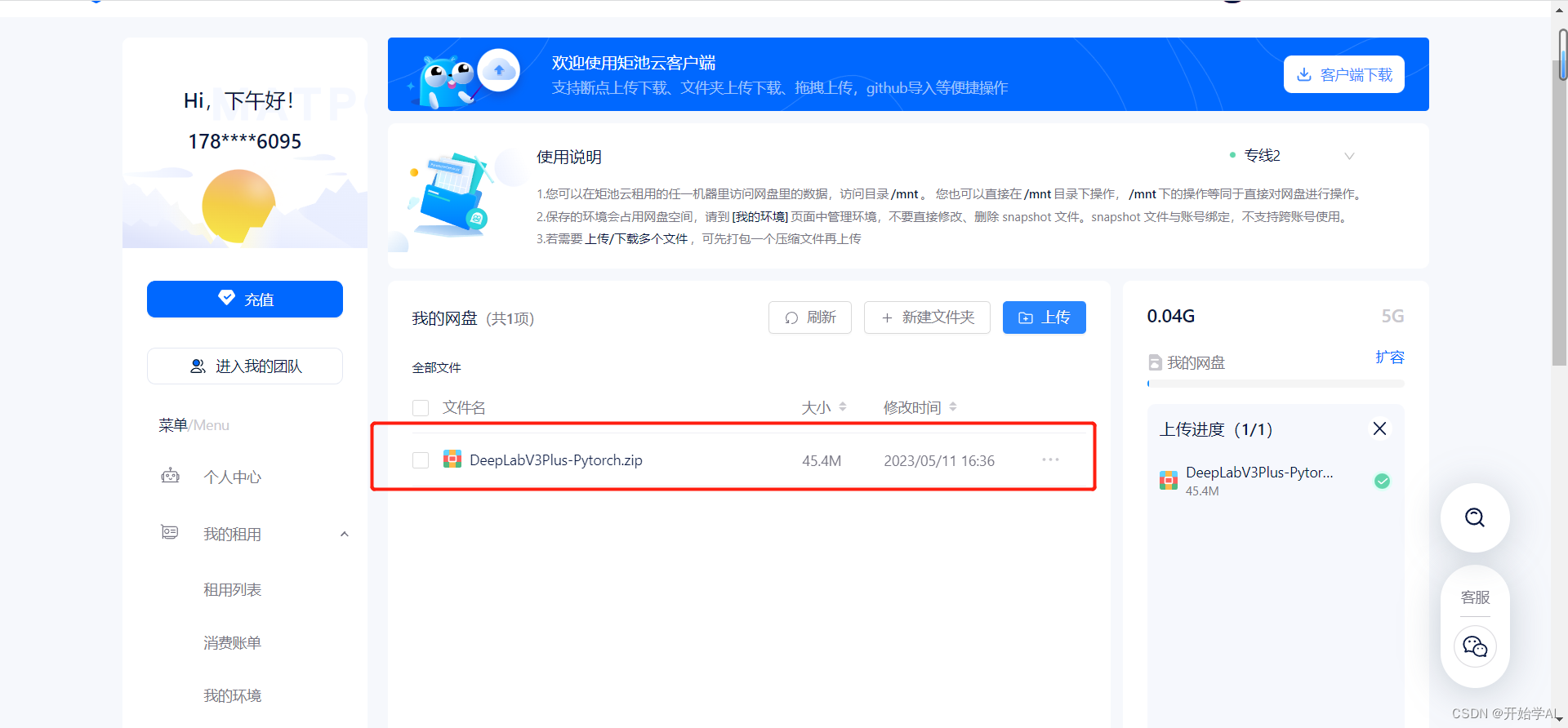
解压:
unzip DeepLabV3Plus-Pytorch.zip -d DeepLabV3Plus-Pytorch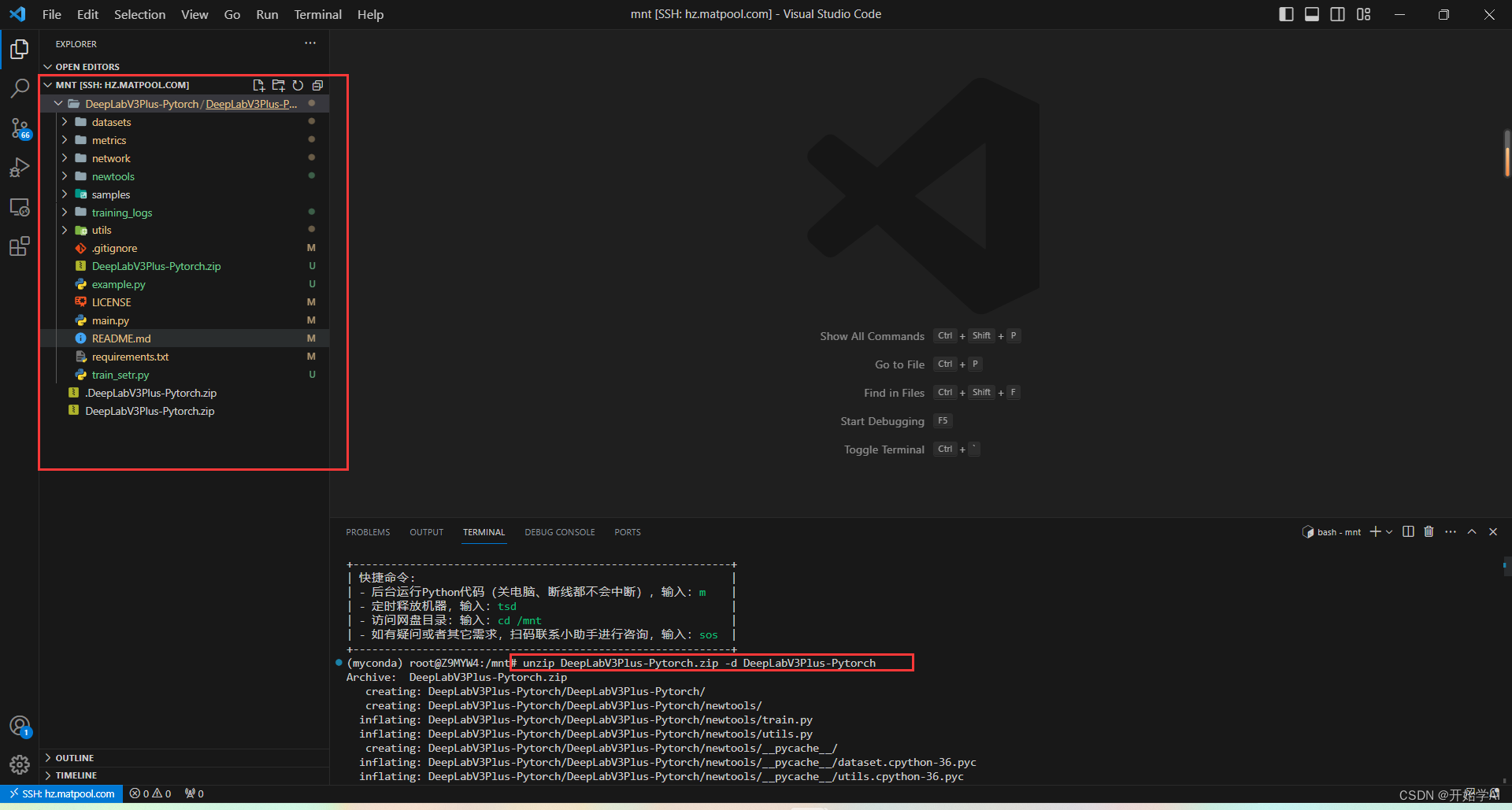
五、进入项目路径
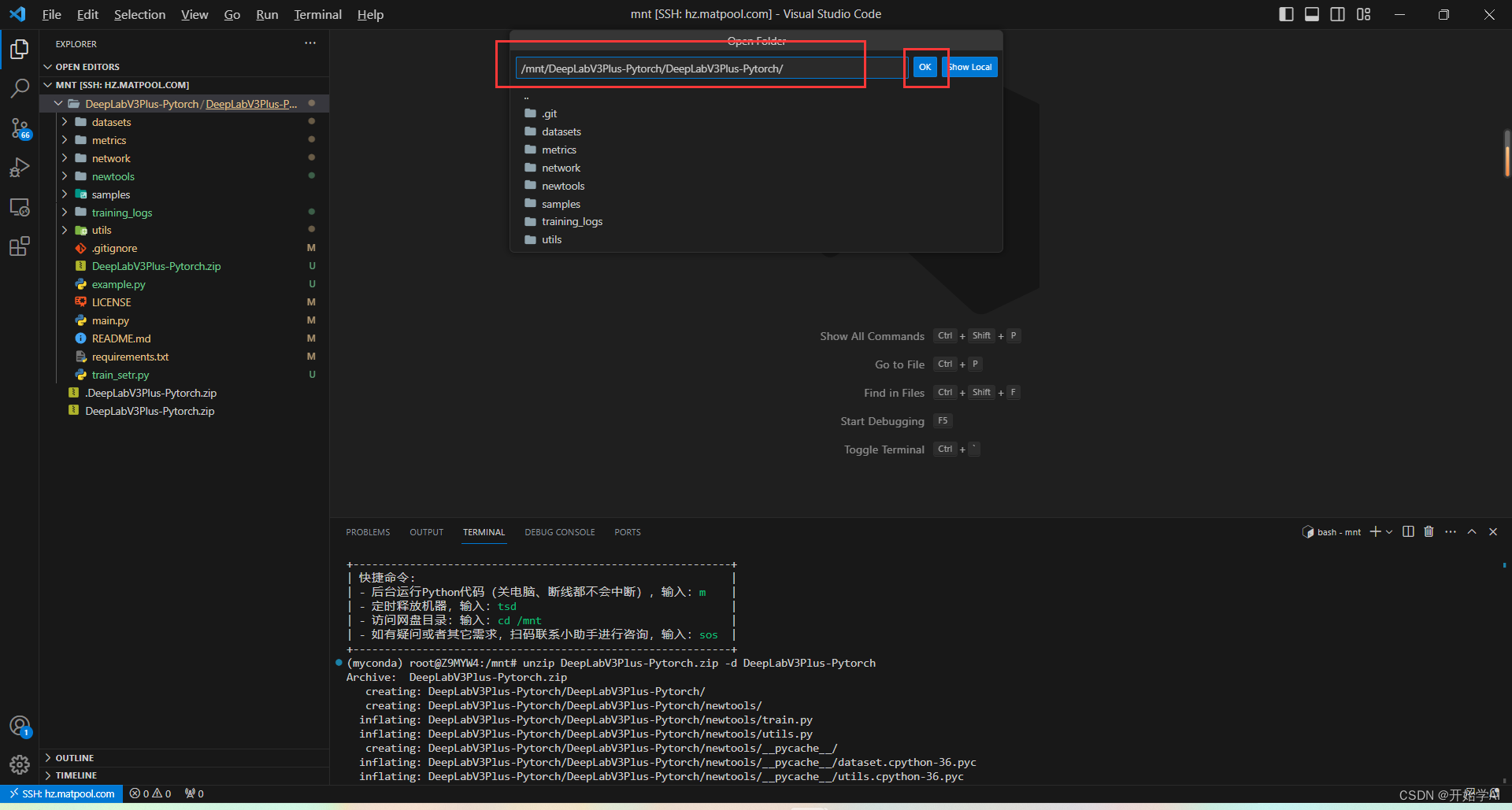
建立以下文件夹,并上传需要检测的图片到该文件夹下
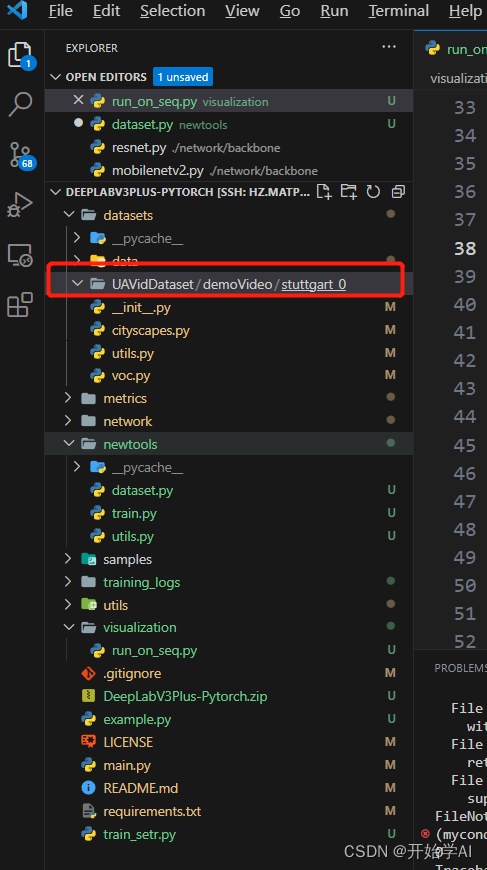
上传数据后,会有以下的临时文件,需要删除以下临时文件。
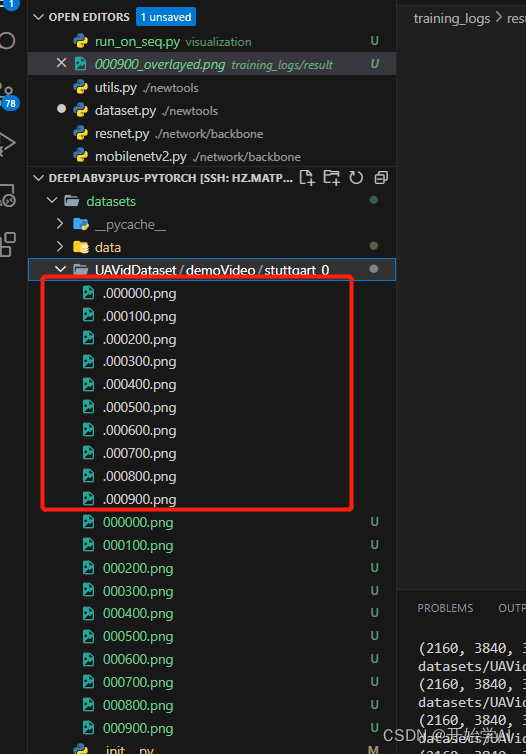
training_logs下创建checkpoint文件夹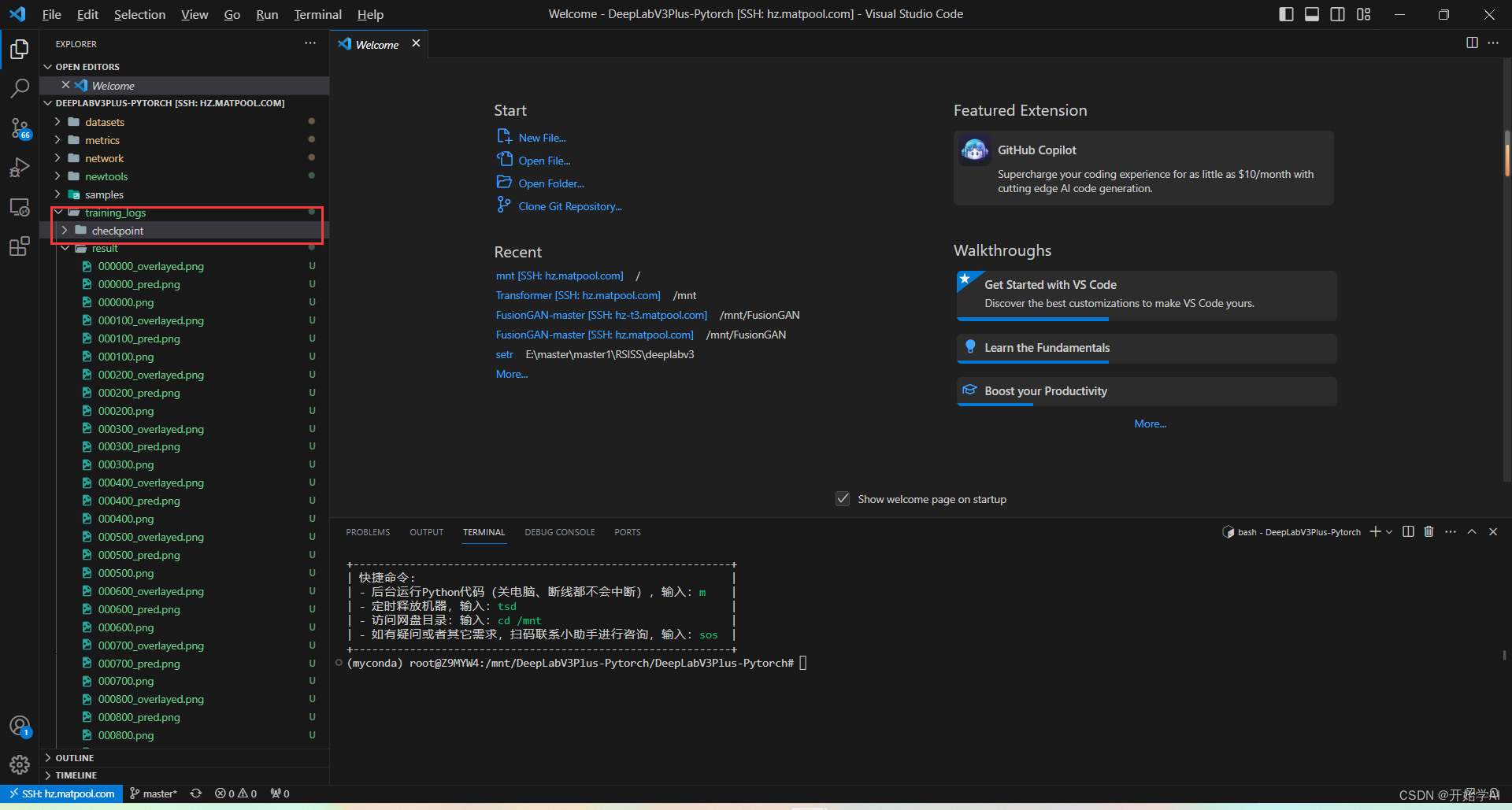
将训练好的权重上传到checkpoint文件夹中:
建立可视化文件夹 visualization
在visualization文件夹下新建run_on_seq.py,并粘贴以下内容:
python"># camera-ready
import sys
sys.path.insert(0, '.')
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
import torch
import torch.utils.data
import torch.nn as nn
from torch.autograd import Variable
import torch.optim as optim
import torch.nn.functional as F
import numpy as np
import pickle
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
import cv2
import network
from newtools.dataset import DatasetSeq
from newtools.utils import label_img_to_color
if __name__ =="__main__":
batch_size = 2
model_map = {
'deeplabv3_resnet50': network.deeplabv3_resnet50,
'deeplabv3plus_resnet50': network.deeplabv3plus_resnet50,
'deeplabv3_resnet101': network.deeplabv3_resnet101,
'deeplabv3plus_resnet101': network.deeplabv3plus_resnet101,
'deeplabv3_mobilenet': network.deeplabv3_mobilenet,
'deeplabv3plus_mobilenet': network.deeplabv3plus_mobilenet
}
network = model_map["deeplabv3plus_resnet101"](num_classes=8, output_stride=16)
network.cuda()
network.load_state_dict(torch.load("training_logs/checkpoint/model_DeeplabV3Plus_epoch_200.pth"))
for sequence in ["0"]:
print (sequence)
val_dataset = DatasetSeq(uavid_data_path="datasets/UAVidDataset",
uavid_meta_path="datasets/UAVidDataset",
sequence=sequence)
num_val_batches = int(len(val_dataset)/batch_size)
print ("num_val_batches:", num_val_batches)
val_loader = torch.utils.data.DataLoader(dataset=val_dataset,
batch_size=batch_size, shuffle=False,
num_workers=1)
network.eval() # (set in evaluation mode, this affects BatchNorm and dropout)
unsorted_img_ids = []
for step, (imgs, img_ids) in enumerate(val_loader):
with torch.no_grad(): # (corresponds to setting volatile=True in all variables, this is done during inference to reduce memory consumption)
imgs = Variable(imgs).cuda() # (shape: (batch_size, 3, img_h, img_w))
outputs = network(imgs) # (shape: (batch_size, num_classes, img_h, img_w))
####################################################################
# save data for visualization:
####################################################################
outputs = outputs.data.cpu().numpy() # (shape: (batch_size, num_classes, img_h, img_w))
pred_label_imgs = np.argmax(outputs, axis=1) # (shape: (batch_size, img_h, img_w))
pred_label_imgs = pred_label_imgs.astype(np.uint8)
for i in range(pred_label_imgs.shape[0]):
pred_label_img = pred_label_imgs[i] # (shape: (img_h, img_w))
img_id = img_ids[i]
img = imgs[i] # (shape: (3, img_h, img_w))
img = img.data.cpu().numpy()
img = np.transpose(img, (1, 2, 0)) # (shape: (img_h, img_w, 3))
img = img*np.array([0.229, 0.224, 0.225])
img = img + np.array([0.485, 0.456, 0.406])
img = img*255.0
img = img.astype(np.uint8)
pred_label_img_color = label_img_to_color(pred_label_img)
overlayed_img = 0.35*img + 0.65*pred_label_img_color
overlayed_img = overlayed_img.astype(np.uint8)
img_h = overlayed_img.shape[0]
img_w = overlayed_img.shape[1]
cv2.imwrite("training_logs/result" + "/" + img_id + ".png", img)
cv2.imwrite("training_logs/result" + "/" + img_id + "_pred.png", pred_label_img_color)
cv2.imwrite("training_logs/result" + "/" + img_id + "_overlayed.png", overlayed_img)
unsorted_img_ids.append(img_id)
############################################################################
# create visualization video:
############################################################################
out = cv2.VideoWriter("%s/stuttgart_%s_combined.avi" % ("training_logs/result", sequence), cv2.VideoWriter_fourcc(*"MJPG"), 20, (2*img_w, 2*img_h))
sorted_img_ids = sorted(unsorted_img_ids)
for img_id in sorted_img_ids:
img = cv2.imread("training_logs/result" + "/" + img_id + ".png", -1)
pred_img = cv2.imread("training_logs/result" + "/" + img_id + "_pred.png", -1)
overlayed_img = cv2.imread("training_logs/result" + "/" + img_id + "_overlayed.png", -1)
combined_img = np.zeros((2*img_h, 2*img_w, 3), dtype=np.uint8)
combined_img[0:img_h, 0:img_w] = img
combined_img[0:img_h, img_w:(2*img_w)] = pred_img
combined_img[img_h:(2*img_h), (int(img_w/2)):(img_w + int(img_w/2))] = overlayed_img
out.write(combined_img)
out.release()
运行:
python">python visualization/run_on_seq.py报错:
File "/mnt/DeepLabV3Plus-Pytorch/DeepLabV3Plus-Pytorch/./network/backbone/mobilenetv2.py", line 2, in <module>
from torchvision.models.utils import load_state_dict_from_url
ModuleNotFoundError: No module named 'torchvision.models.utils'
解决办法:将错误语句换为以下语句
from torch.hub import load_state_dict_from_url再运行:
python">python visualization/run_on_seq.py可生成预测结果。保存在training_logs/result目录下。
六、DeeplabV3Plus论文解读
论文地址:https://arxiv.org/pdf/1802.02611.pdf
DeepLabv 3+通过添加一个简单而有效的解码器模块来扩展DeepLabv 3,以细化分割结果,特别是对象边界。
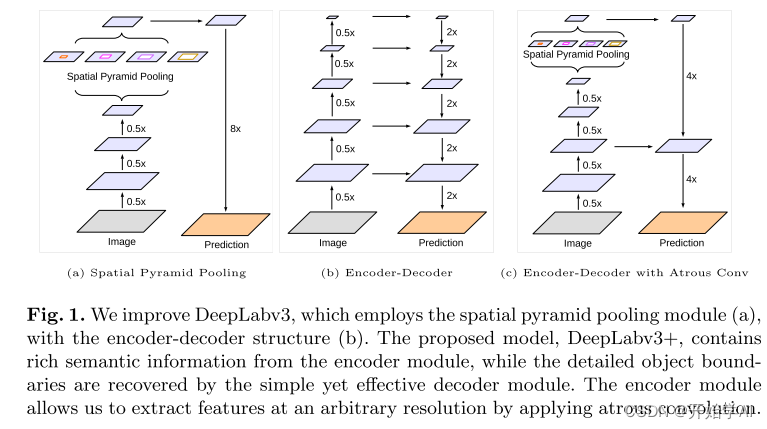
我们改进了DeepLabv 3,它采用了空间金字塔池化模块(a),具有编码器-解码器结构(b)。所提出的模型DeepLabv 3+包含来自编码器模块的丰富语义信息,而详细的对象边界由简单而有效的解码器模块恢复。编码器模块允许我们通过应用atrous卷积以任意分辨率提取特征。
空间金字塔池化参考资料:https://zhuanlan.zhihu.com/p/64510297
总结:SPP的本质就是多层maxpool,只不过为了对于不同尺寸大小 的featur map 生成固定大小的输出。
- 可以提取不同尺寸的空间特征信息,可以提升模型对于空间布局和物体变性的鲁棒性。
- 可以避免将图片resize、crop成固定大小输入模型的弊端。
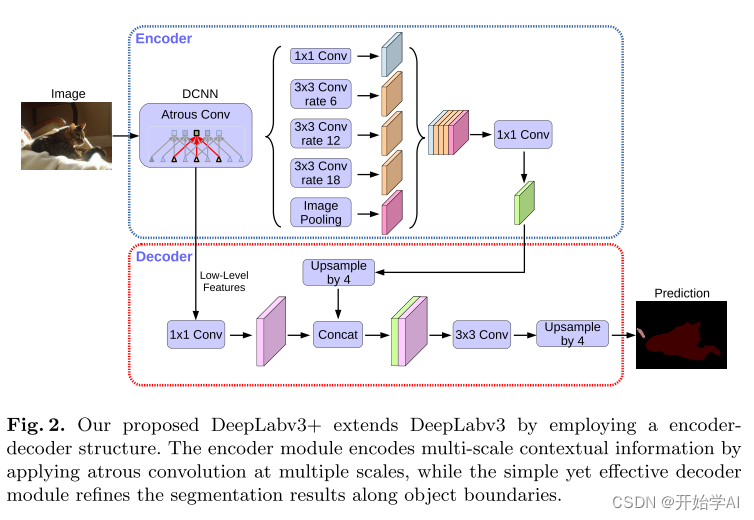
我们提出的DeepLabv3+通过采用编码器解码器结构扩展了DeepLabv3。编码器模块通过在多个尺度上应用atrous卷积来编码多尺度上下文信息,而简单而有效的解码器模块沿着对象边界细化分割结果。
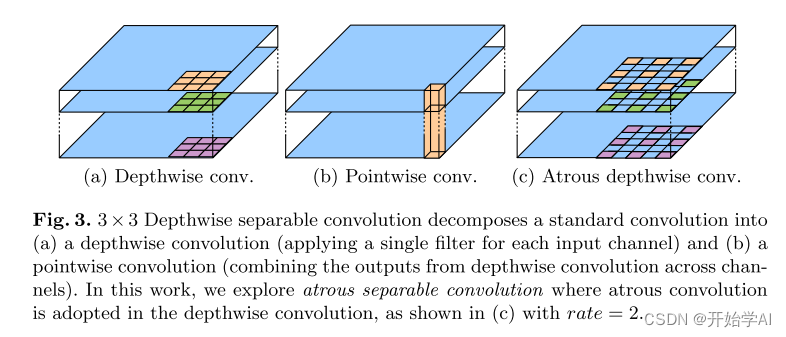
Atrous卷积是一个强大的工具,它允许我们显式控制深度卷积神经网络计算出的特征图分辨率,并调整滤波器的Atrous rate以捕获多尺度信息 。
DeeplabV3Plus总结:
编码器:
1. 在图像分类中,下采样倍率是32,语义分割中,下采样倍率一般为16或8,对于语义分割的任务,比如 可以在ResNet中,通过移除最后一个(或两个)块中的步幅并相应地应用atrous卷积(例如,对于输出stride= 8,我们将空洞卷积率= 2和空洞卷积率= 4分别应用于最后两个块)。
2. 此外,DeepLabv3PLus 使用了 Atrous空间金字塔池化模块,该模块通过应用具有不同速率的Atrous卷积来探测多个尺度的卷积特征。
解码器:
因此,我们提出了一种简单而有效的解码器模块,如图2所示。.编码器特征首先以因子4进行双线性上采样,然后与来自网络主干的具有相同空间分辨率的对应低级特征进行级联[73](例如,在ResNet-101中跨步之前的Conv 2 [25])。在级联之后,我们应用一些3 × 3卷积来细化特征,然后再进行一次简单的双线性上采样,采样系数为4。