Exploring Cross-Image Pixel Contrast for Semantic Segmentation
探索语义分割的跨图像像素对比度
Paper:https://openaccess.thecvf.com/content/ICCV2021/html/Wang_Exploring_Cross-Image_Pixel_Contrast_for_Semantic_Segmentation_ICCV_2021_paper.html
Code:https://github.com/tfzhou/ContrastiveSeg
Video:https://www.youtube.com/watch?v=roWqXRZPhmk
Abstract
当前的语义分割方法仅侧重于通过上下文聚合模块(例如,扩张卷积、神经注意力)或结构感知优化标准(例如,类 IoU 损失)来挖掘“局部”上下文,即各个图像内像素之间的依赖关系。然而,他们忽略了训练数据的“全局”上下文,即不同图像的像素之间丰富的语义关系。
受无监督对比表示学习最新进展的启发,我们提出了一种在完全监督环境下进行语义分割的逐像素对比算法。核心思想是强制属于同一语义类的像素嵌入比来自不同类的嵌入更相似。它通过明确探索以前很少探索的标记像素的结构,提出了用于语义分割的像素级度量学习范例。我们的方法可以轻松地合并到现有的分割框架中,而在测试期间无需额外的开销。
我们通过实验表明,利用著名的分割模型(即 DeepLabV3、HRNet、OCR)和骨干网(即 ResNet、HRNet),我们的方法在不同数据集(即 Cityscapes、PASCAL-Context、COCO-Stuff、CamVid)上带来了性能改进)。我们希望这项工作将鼓励我们的社区重新思考当前语义分割中事实上的训练范例。
1 Introduction
语义分割旨在推断图像中所有像素的语义标签,是计算机视觉中的一个基本问题。在过去的十年中,在大规模数据集(例如 Cityscapes [15])的可用性和卷积网络(例如 VGG [63]、ResNet [32])的快速发展的推动下,语义分割取得了显着的进展。作为分割模型(例如,全卷积网络(FCN)[51])。特别是,FCN[51]由于其在端到端像素级表示学习方面的独特优势,成为现代分割深度学习技术的基石。然而,其空间不变性阻碍了对像素之间(图像内)有用上下文进行建模的能力。因此,后续工作的主流是深入研究有效上下文聚合的网络设计,例如扩张卷积[80,8,9]、空间金字塔池化[84]、多层特征融合[58,47]和神经注意力[35] ,24]。此外,由于广泛采用的逐像素交叉熵损失从根本上缺乏空间区分能力,因此提出了一些替代优化标准来在分割网络训练期间明确解决对象结构[40,2,86]。
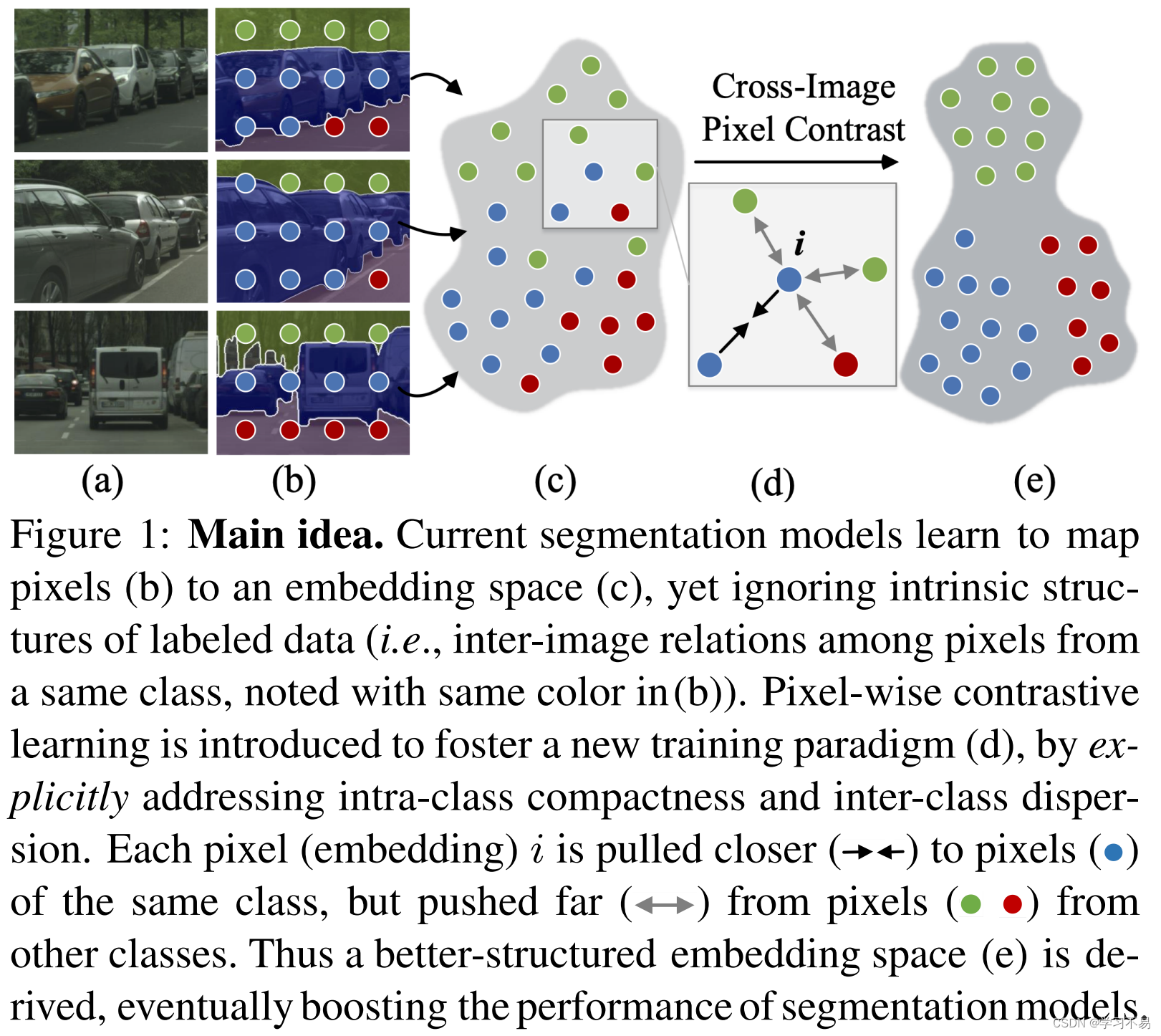
基本上,这些分割模型(不包括[37])利用深层架构将图像像素投影到高度非线性的嵌入空间中(图1(c))。然而,他们通常学习的嵌入空间仅利用像素样本周围的“局部”上下文(即单个图像内的像素依赖性),但忽略整个数据集的“全局”上下文(即图像之间的像素语义关系)。
因此,该领域长期以来一直忽视一个基本问题:一个好的分割嵌入空间应该是什么样子?
理想情况下,它不仅应该 1) 解决单个像素嵌入的分类能力,而且 2) 具有良好的结构,以解决类内紧凑性和类间分散性问题。关于2),在嵌入空间中,来自同一类的像素应该比来自不同类的像素更接近。先前关于表示学习的研究 [49, 60] 也表明,对训练数据的内在结构进行编码(即 2))将有助于特征判别性(即 1))。因此我们推测,尽管现有算法已经取得了令人印象深刻的性能,但通过考虑 1) 和 2) 可以学习更好的结构化像素嵌入空间。
无监督表示学习 [12, 31] 的最新进展可归因于对比学习的复兴——深度度量学习的重要分支 [39]。核心思想是“学习比较”:给定一个锚点,在投影的嵌入空间中将相似(或正)样本与一组不相似(或负)样本区分开来。特别是在计算机视觉领域,基于图像特征向量来评估对比度;锚图像的增强版本被视为正图像,而数据集中的所有其他图像则被视为负图像。
无监督对比学习的巨大成功和我们前面提到的推测共同促使我们重新思考当前语义分割中事实上的训练范式。基本上,无监督对比学习的力量源于结构化比较损失,它利用了训练数据中的上下文。有了这种见解,我们提出了一种逐像素对比算法,以便在完全监督的环境中更有效地进行密集表示学习。具体来说,除了采用逐像素交叉熵损失来解决类别歧视(即属性 1))之外,我们还利用逐像素对比损失通过探索标记像素样本的结构信息来进一步塑造像素嵌入空间(即属性 2))。逐像素对比损失的想法是计算像素到像素的对比度:强制嵌入对于正像素是相似的,对于负像素是不相似的。由于训练时给出了像素级分类信息,正样本是属于同一类的像素,负样本是来自不同类的像素(图1(d))。通过这种方式,可以捕获嵌入空间的全局属性(图1(e)),以更好地反映训练数据的内在结构并实现更准确的分割预测。
通过我们的监督像素对比算法,开发了两种新技术。首先,我们提出了一个区域内存库来更好地解决语义分割的本质。面对大量高度结构化的像素训练样本,我们让内存存储语义区域的池化特征(即来自同一图像的具有相同语义标签的像素),而不是仅存储像素级嵌入。这导致了像素到区域对比度,作为像素到像素对比度策略的补充。这样的内存设计使我们能够在每个训练步骤中访问更具代表性的数据样本,并充分探索像素和语义级片段之间的结构关系,即属于同一类的像素和片段在嵌入空间中应该接近。其次,我们提出了不同的采样策略,以更好地利用信息样本,让分割模型更加关注那些分割困难的像素。之前的工作已经证实硬负例对于度量学习至关重要[39,60,62],我们的研究进一步揭示了在这种监督的密集图像预测任务中挖掘信息丰富的负例/正例和锚点的重要性。
简而言之,我们的贡献有三方面:
- 我们提出了一种用于语义分割的监督式逐像素对比学习方法。它将当前的图像训练策略提升到图像间、像素到像素的范式。它本质上是通过充分利用标记像素之间的全局语义相似性来学习结构良好的像素语义嵌入空间。
- 我们开发了区域存储器,以更好地探索大型视觉数据空间并支持进一步计算像素到区域的对比度。与像素到像素对比度计算相结合,我们的方法利用了像素之间以及像素与语义区域之间的语义相关性。
- 我们证明可以提供具有更好示例和锚点采样策略的更强大的分割模型,而不是选择随机像素样本。
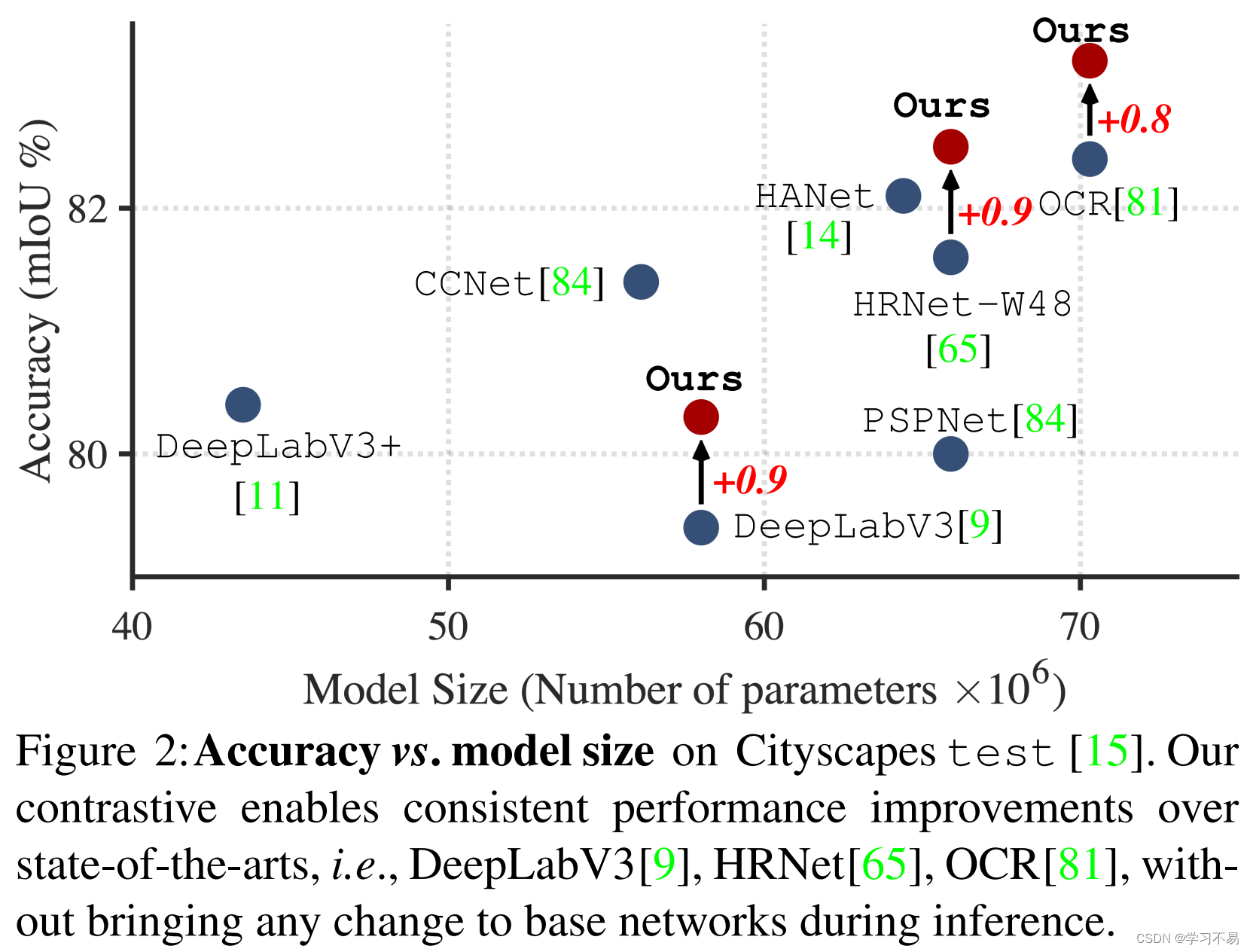
我们的方法可以无缝地合并到现有的分割网络中,无需对基本模型进行任何更改,并且在测试期间不会产生额外的推理负担(图 2)。因此,我们的方法显示,在具有挑战性的数据集(即 Cityscapes [15]、PASCAL-Context [53]、COCO-Stuff[5] 和 CamVid[3])上,使用 state-of-最先进的分割架构(即 DeepLabV3 [9]、HRNet [65] 和 OCR [81])和标准主干网(即 ResNet [32]、HRNet [65])。令人印象深刻的结果揭示了度量学习在密集图像预测任务中的前景。我们希望这项工作能够深入了解全局像素关系在分割网络训练中的关键作用,并促进对所提出的开放问题的研究。
2 Related Work
我们的工作借鉴了语义分割、对比学习和深度度量学习方面的现有文献。为了简洁起见,仅讨论最相关的作品。
Semantic Segmentation
FCN[51]极大地促进了语义分割的进步。它擅长端到端密集特征学习,但是只能通过局部感受野感知有限的视觉上下文。由于图像中的像素之间存在强依赖性,并且这些依赖性提供了有关对象结构的信息[70],因此如何捕获这种依赖性成为进一步改进 FCN 的重要问题。主要的后续工作尝试聚合多个像素来显式地建模上下文,例如,利用不同大小的卷积/池化内核或膨胀率来收集多尺度视觉线索[80,84,8,9],构建图像金字塔从多分辨率输入中提取上下文,采用 Encoder Decoder 架构合并多层特征 [58, 47, 66],应用 CRF 恢复详细结构 [50, 87],并采用神经注意力 [67, 29]直接交换成对像素之间的上下文[10,35,36,24]。除了研究上下文聚合网络模块之外,另一项工作转向设计上下文感知优化目标[40,2,86],即在训练期间直接验证分割结构,以取代像素级交叉熵损失。
尽管令人印象深刻,但这些方法仅解决单个图像内的像素依赖性,忽略了标记数据的全局上下文,即不同训练图像之间的像素语义相关性。通过逐像素对比学习公式,我们将不同类别的像素映射到更独特的特征。学习到的像素特征不仅可以区分图像内的语义分类,更重要的是,可以区分图像之间的语义分类。
Contrastive Learning
最近,学习无标签表示的最引人注目的方法是无监督对比学习[55,34,73,13,12],它显着优于其他基于借口任务的替代方法[43,26,18,54]。与范例学习[19]类似,对比方法通过将相似(正)数据对与不相似(负)数据对进行对比,以区分的方式学习表示。随后研究的一个主要分支集中于如何选择正负对。对于图像数据,标准的正对采样策略是应用强扰动来创建每个图像数据的多个视图[73,12,31,34,6]。负对通常是随机采样的,但最近提出了一些硬负例挖掘策略[41,57,38]。此外,为了在对比计算期间存储更多负样本,采用固定[73]或动量更新[52, 31]存储器。一些最新的研究[41,33,71]也证实标签信息可以帮助基于对比学习的图像级模式预训练。
我们提出了一种在完全监督的环境下进行语义分割的像素到像素对比学习方法。它产生了一种新的训练协议,可探索标记数据中的全局像素关系,以规范分割嵌入空间。尽管一些同时进行的工作也解决了密集图像预测中的对比学习问题 [75,7,69],但想法却有显着不同。
首先,他们通常将对比学习视为密集图像嵌入的预训练步骤。其次,它们只是使用单个图像中的局部上下文,即仅计算同一图像的增强版本的像素之间的对比度。第三,他们没有注意到度量学习在补充当前完善的基于像素交叉熵损失的训练机制方面的关键作用(参见§3.2)。
[75] Propagate Yourself: Exploring Pixel-Level Consistency for Unsupervised Visual Representation Learning
[7] Contrastive learning of global and local features for medical image segmentation with limited annotations
[69] Dense Contrastive Learning for Self-Supervised Visual Pre-Training
Deep Metric Learning
度量学习的目标是使用最佳距离度量来量化样本之间的相似性。对比损失[28]和三元组损失[60]是深度度量学习损失函数的两种基本类型。与分别增加和减少相似数据样本和不相似数据样本之间的距离类似的精神,前者将成对的样本作为输入,而后者则由三元组组成。深度度量学习[22]已被证明在各种计算机视觉任务中有效,例如图像检索[64]和人脸识别[60]。
尽管一些先前的方法解决了语义分割中度量学习的想法,但它们仅考虑对象[29]或实例[16,1,22,42]的本地内容。值得注意的是[37]还探索了训练数据的跨图像信息,即利用感知像素组进行非参数像素分类。由于其基于聚类的度量学习策略,[37]需要检索额外的标记数据进行推理。不同的是,我们的核心思想,即利用图像间像素到像素的相似性来对嵌入空间实施全局约束,在概念上是新颖的,以前很少被探索过。它通过紧凑的训练范例执行,该范例具有一元、像素级交叉熵损失和成对、像素间对比度损失的互补优势,并且在部署期间不会给基础网络带来任何额外的推理成本或修改。
3 Methodology
在详细介绍用于语义分割的有监督像素对比算法(第 3.2 节)之前,我们首先介绍无监督视觉表示学习中的对比公式和记忆库的概念(第 3.1 节)。
3.1 Preliminaries
Unsupervised Contrastive Learning
无监督视觉表示学习旨在学习 CNN 编码器
f
C
N
N
f_{CNN}
fCNN,将每个训练图像
I
I
I 转换为特征向量
v
=
f
C
N
N
(
I
)
∈
R
D
v = f_{CNN}(I) \in \mathbb{R}^D
v=fCNN(I)∈RD,使得
v
v
v 最好地描述
I
I
I。为了实现这一目标,对比方法通过区分正图像来进行训练。 (锚点
I
I
I 的增强版本),基于样本之间的相似性原则,从多个负片(从训练集中随机抽取的图像,不包括
I
I
I)。一种流行的对比学习损失函数称为 InfoNCE [27, 55],采用以下形式:
L I N C E = − l o g e x p ( v ⋅ v + / τ ) e x p ( v ⋅ v + / τ ) + ∑ v − ∈ N I e x p ( v ⋅ v − / τ ) (1) \mathcal{L}^{NCE}_I = - log \frac{exp(v \cdot v^+ / \tau)}{exp(v \cdot v^+ / \tau) + \sum_{v^- \in \mathcal{N}_I}exp(v \cdot v^- / \tau)} \tag{1} LINCE=−logexp(v⋅v+/τ)+∑v−∈NIexp(v⋅v−/τ)exp(v⋅v+/τ)(1)
其中 v + v^+ v+ 是 I I I 正值的嵌入, N I \mathcal{N}_I NI 包含负值的嵌入,“ ⋅ \cdot ⋅”表示内(点)积, τ > 0 \tau > 0 τ>0 是温度超参数。请注意,损失函数中的所有嵌入都是“ l 2 \mathcal{l}_2 l2-归一化”的。
Memory Bank
正如最近的研究[73,13,31]所揭示的,大量的负数(即
∣
N
I
∣
|\mathcal{N}_I|
∣NI∣)在无监督对比表示学习中至关重要。由于底片的数量受到小批量大小的限制,最近的对比方法利用大型外部存储器作为存储更多导航样本的库。具体来说,一些方法[73]直接将所有训练样本的嵌入存储在内存中,但是很容易受到异步更新的影响。其他一些人选择保留最后几个批次的队列 [68,13,31] 作为内存。在[13, 31]中,存储的嵌入甚至通过编码器网络
f
C
N
N
f_{CNN}
fCNN 的动量更新版本进行动态更新。
3.2 Supervised Contrastive Segmentation
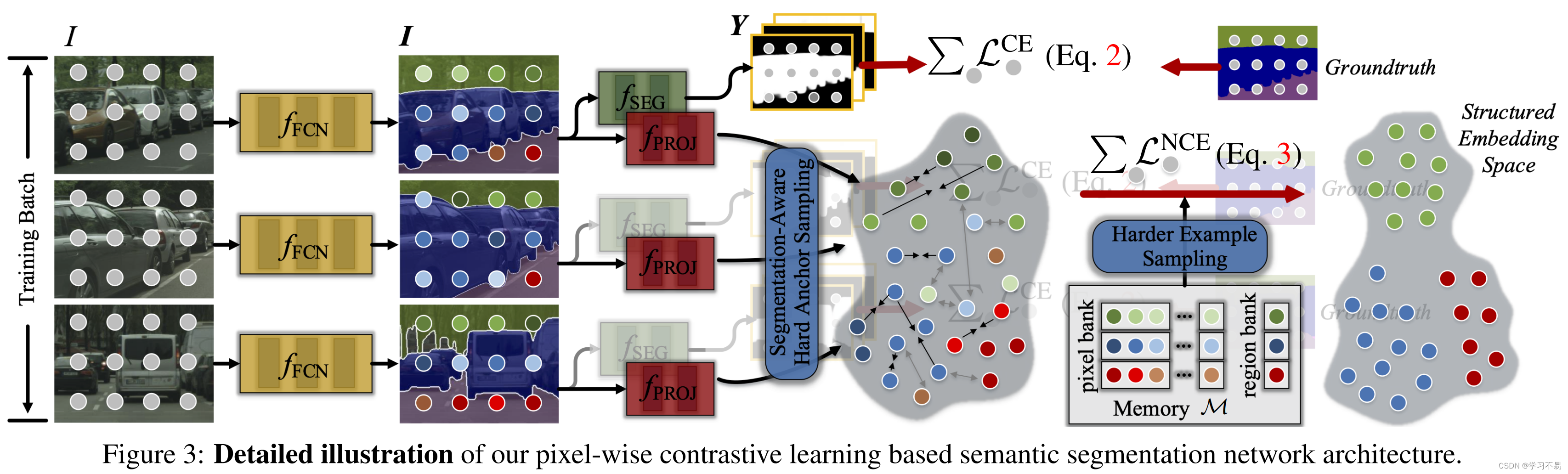
Pixel-Wise Cross-Entropy Loss
在语义分割的背景下,图像
I
I
I 的每个像素
i
i
i 必须被分类为语义类
c
∈
C
c \in C
c∈C。当前的方法通常将此任务视为逐像素分类问题。具体来说,让
f
F
C
N
f_{FCN}
fFCN 是一个 FCN 编码器(例如 ResNet [32]),它为
I
I
I 生成密集特征
I
∈
R
H
×
W
×
D
I \in \mathbb{R}^{H \times W \times D}
I∈RH×W×D,从中可以导出
i
i
i 的像素嵌入
i
∈
R
D
i \in \mathbb{R}^D
i∈RD (即,
i
∈
I
i \in I
i∈I)。然后,分割头
f
S
E
G
f_{SEG}
fSEG将
I
I
I 映射到分类分数图
Y
=
f
S
E
G
(
I
)
∈
R
H
×
W
×
D
Y = f_{SEG}(I) \in \mathbb{R}^{H \times W \times D}
Y=fSEG(I)∈RH×W×D。进一步设
y
=
[
y
1
,
⋅
⋅
⋅
,
y
∣
C
∣
]
∈
R
∣
C
∣
y = [y_1,···, y_{|C|}] \in \mathbb{R}^{|C|}
y=[y1,⋅⋅⋅,y∣C∣]∈R∣C∣ 是像素
i
i
i 的非归一化得分向量(称为 logit),源自
Y
Y
Y ,即
y
∈
Y
y \in Y
y∈Y 。给定像素
i
i
i 的
y
y
y 与它的真实标签
c
‾
∈
C
\overline{c} \in C
c∈C,交叉熵损失使用 softmax 进行优化(参见图 3):
L i C E = − 1 c ‾ T l o g ( s o f t m a x ( y ) ) (2) \mathcal{L}^{CE}_i = -1^T_{\overline{c}} log(softmax(y)) \tag{2} LiCE=−1cTlog(softmax(y))(2)
其中
1
c
‾
1_{\overline{c}}
1c 表示
c
‾
\overline{c}
c 的 one-hot 编码,对数定义为逐元素,并且
s
o
f
t
m
a
x
(
y
c
)
=
e
x
p
(
y
c
)
∑
c
′
=
1
∣
c
∣
e
x
p
(
y
c
′
)
softmax(y_c) = \frac{exp(y_c)}{\sum^{|c|}_{c\prime=1}exp(y_{c\prime})}
softmax(yc)=∑c′=1∣c∣exp(yc′)exp(yc)。这种培训目标设计主要受到两个限制。
1)它独立地惩罚像素级预测,但忽略像素之间的关系[86]。
2)由于使用了softmax,损失仅取决于logits之间的相对关系,不能直接监督学习到的表示[56]。这两个问题很少被注意到;只有少数结构感知损失被设计来解决1),通过考虑像素亲和力[40],优化交集测量[2],或最大化真实值和预测图之间的互信息[86]。然而,这些替代损失仅考虑图像内像素之间的依赖性(即局部上下文),而不考虑图像之间像素之间的语义相关性(即全局结构)。
[40] Adaptive Affinity Fields for Semantic Segmentation
[2] The Lovász-Softmax Loss: A Tractable Surrogate for the Optimization of the Intersection-Over-Union Measure in Neural Networks
[86] Region Mutual Information Loss for Semantic Segmentation
Pixel-to-Pixel Contrast
在这项工作中,我们开发了一种像素对比学习方法,通过规范嵌入空间并探索训练数据的全局结构,解决 1) 和 2) 问题。我们首先将方程(1)扩展到我们的监督密集图像预测设置。基本上,我们的对比损失计算中的数据样本是训练图像像素。此外,对于具有真实语义标签
c
‾
\overline{c}
c 的像素
i
i
i,正样本是也属于类
c
‾
\overline{c}
c 的其他像素,而负样本是属于其他类
C
/
c
‾
C /\ \overline{c}
C/ c的像素。我们的监督式逐像素对比损失定义为:
L i N C E = 1 ∣ P i ∣ ∑ i + ∈ P i − l o g e x p ( i ⋅ i + / τ ) e x p ( i ⋅ i + / τ ) + ∑ i − ∈ N i e x p ( i ⋅ i − / τ ) (3) \mathcal{L}^{NCE}_i = \frac{1}{|\mathcal{P}_i|} \sum_{i^+ \in \mathcal{P}_i} -log \frac{exp(i \cdot i^+ / \tau)}{exp(i \cdot i^+ / \tau) + \sum_{i^- \in \mathcal{N}_i} exp(i \cdot i^- /\tau)} \tag{3} LiNCE=∣Pi∣1i+∈Pi∑−logexp(i⋅i+/τ)+∑i−∈Niexp(i⋅i−/τ)exp(i⋅i+/τ)(3)
其中 P i \mathcal{P}_i Pi 和 N i \mathcal{N}_i Ni 分别表示像素 i i i 的正样本和负样本的像素嵌入集合。请注意,正/负样本和锚点 i i i 不限于来自同一图像。如方程(3)所示,这种基于像素到像素对比度的损失设计的目的是通过将同一类像素样本拉近并将不同类样本推开来学习嵌入空间。
等式(2)中的像素交叉熵损失和等式(3)中的对比损失是互补的;前者让分割网络学习对分类有意义的判别性像素特征,而后者通过显式探索像素样本之间的全局语义关系,有助于规范嵌入空间,提高类内紧凑性和类间可分离性。因此总体训练目标是:
L S E G = ∑ i ( L i C E + λ L i N C E ) (4) \mathcal{L}^{SEG} = \sum_i (\mathcal{L}^{CE}_i + \lambda \mathcal{L}^{NCE}_i) \tag{4} LSEG=i∑(LiCE+λLiNCE)(4)
其中 λ > 0 \lambda > 0 λ>0 是系数。如图 4 所示, L S E G L^{SEG} LSEG 学习到的像素嵌入变得更加紧凑且分离良好。这表明,通过利用一元交叉熵损失和成对度量损失的优势,分割网络可以生成更具辨别力的特征,从而产生更有希望的结果。稍后在第 4.2 节和第 4.3 节中提供了定量分析。

Pixel-to-Region Contrast
如第 3.1 节所述,记忆是一项关键技术,有助于对比学习利用海量数据来学习良好的表示。然而,由于我们的密集预测设置中有大量的像素样本,并且其中大多数都是冗余的(即从和谐对象区域采样),因此像传统存储器[12]一样直接存储所有训练像素样本,会大大减慢速度学习过程。在队列中维护最后几个批次,例如 [68,13,31],也不是一个好的选择,因为最近的批次仅包含有限数量的图像,降低了像素样本的多样性。因此,我们选择为每个类别维护一个像素队列。对于每个类别,仅从最新小批量中的每个图像中随机选择少量(即
V
V
V )像素,并将其拉入队列,大小为
T
≫
V
T \gg V
T≫V 。在实践中,我们发现这种策略非常高效且有效,但欠采样像素嵌入太稀疏,无法完全捕获图像内容。因此,我们进一步构建了一个区域存储库,用于存储从图像片段(即语义区域)吸收的更具代表性的嵌入。
具体来说,对于总共有 N N N 个训练图像和 ∣ C ∣ |C| ∣C∣ 的分割数据集对于语义类,我们的区域内存的大小为 ∣ C ∣ × N × D |C| \times N \times D ∣C∣×N×D,其中 D D D 是像素嵌入的维度。区域存储器中的第 ( c ‾ , n \overline{c}, n c,n) 个元素是通过平均池化第 n n n 个图像中标记为 c ‾ \overline{c} c 类别的像素的所有嵌入而获得的 D D D 维特征向量。区域内存带来两个优点:1)以较低的内存消耗存储更具代表性的“像素”样本; 2)允许我们的像素对比损失(参见方程(3))进一步探索像素与区域的关系。关于2),计算方程时: (3) 对于属于 c ‾ \overline{c} c 类别的锚像素 i i i,具有相同类别 c c c 的存储区域嵌入被视为正值,而具有其他类别 C / c ‾ C /\ \overline{c} C/ c 的区域嵌入被视为负值。对于像素存储器,大小为 ∣ C ∣ × T × D |C| \times T \times D ∣C∣×T×D。因此,对于整个内存(记为 M \mathcal{M} M),总大小为 ∣ C ∣ × ( N + T ) × D |C| \times (N + T) \times D ∣C∣×(N+T)×D。我们在§4.2 中检查了 M \mathcal{M} M 的设计。在下面的部分中,除非另有说明,我们不会区分 M \mathcal{M} M 中的像素嵌入和区域嵌入。
Hard Example Sampling
先前的研究[60,39,41,57,38]发现,除了损失设计和训练样本的数量之外,训练样本的判别力对于度量学习也至关重要。考虑到我们的情况,逐像素对比损失的梯度(参见方程(3))w.r.t.锚嵌入
i
i
i 可以表示为:
∂ L i N C E ∂ i = − 1 τ ∣ P i ∣ ∑ i + ∈ P i ( ( 1 − p i + ) ⋅ i + − ∑ i − ∈ N i p i − ⋅ i − ) (5) \frac{\partial \mathcal{L}^{NCE}_i}{\partial i} = - \frac{1}{\tau |\mathcal{P}_i|} \sum_{i^+ \in \mathcal{P}_i}((1-p_{i^+}) \cdot i^+ - \sum_{i^- \in \mathcal{N}_i} p_{i^-} \cdot i^-) \tag{5} ∂i∂LiNCE=−τ∣Pi∣1i+∈Pi∑((1−pi+)⋅i+−i−∈Ni∑pi−⋅i−)(5)
其中 p i + / − ∈ [ 0 , 1 ] p_{i^{+/-}} \in [0, 1] pi+/−∈[0,1] 表示正/负 i + / − i^{+/-} i+/− 与锚点 i i i 之间的匹配概率,即 p i + / − = e x p ( i ⋅ i + / − / τ ) ∑ i ′ ∈ P i ∪ N i e x p ( i ⋅ i ′ / τ ) p_{i^{+/-}} = \frac {exp(i \cdot i^{+/-} / \tau)}{\sum_{i\prime \in \mathcal{P}_i \cup \mathcal{N}_i} exp(i \cdot i\prime / \tau)} pi+/−=∑i′∈Pi∪Niexp(i⋅i′/τ)exp(i⋅i+/−/τ) 。我们认为点积(即 i ⋅ i − i \cdot i^− i⋅i−)越接近 1 的负数越难,即与锚点 i 相似的负数。类似地,点积(即 i ⋅ i + i \cdot i^+ i⋅i+)接近 -1 的正值被认为更难,即与 i i i 不同的正值。我们可以发现,较难的负片比较容易的负片带来更多的梯度贡献,即 p i − p_{i^−} pi− 。这一原则也适用于正数,其梯度贡献为 1 − p i + 1 − p_{i^+} 1−pi+。 Kalantidis 等人[38]进一步指出,随着训练的进展,越来越多的负例变得过于简单,无法对无监督对比损失做出重大贡献(参见等式(1))。对于负数和正数来说,这种情况也发生在我们的监督环境中(参见等式(3))。为了解决这个问题,我们提出以下采样策略:
- 最难的示例采样。受到度量学习中最难的负数挖掘的启发[4],我们首先设计了一种“最难的示例采样”策略:对于每个嵌入的锚像素 i i i,仅从内存库 M \mathcal{M} M 中采样前 K K K 个最难的负数和正数,用于计算逐像素对比损失(即等式(3)中的 L N C E L^{NCE} LNCE)。
- 半困难示例采样。一些研究建议使用更难的负数,因为使用最难的负数进行度量学习的优化可能会导致不良的局部最小值[60,74,23]。因此,我们进一步设计了一种“半硬示例采样”策略:对于每个锚嵌入 i i i,我们首先从记忆库 M \mathcal{M} M 中收集前 10% 最近的负例(分别是前 10% 最远的正例),然后从中随机采样 K K K 我们的对比损失计算的负数(分别是 K K K 个正数)。
- 分段感知硬锚采样。我们不是挖掘信息丰富的正面和负面例子,而是制定锚定抽样策略。我们将锚嵌入的分类能力视为其在对比学习中的重要性。这导致了“分段感知硬锚采样”:预测不正确的像素,即 c ≠ c ‾ c \neq \overline{c} c=c,被视为硬锚。对于对比损失计算(参见等式(3)),一半锚点是随机采样的,一半是硬锚点。这种锚点采样策略使我们的对比学习能够更多地关注难以分类的像素,从而提供更多的分段感知嵌入。
在实践中,我们发现“半困难示例采样”策略比“最难示例采样”策略表现更好。 此外,采用“分割感知硬锚采样”策略后,分割性能可以进一步提高。相关实验见§4.2。
5 Conclusion and Discussion
在本文中,我们提出了一种新的语义分割监督学习范式,具有一元分类和结构化度量学习的互补优势。
通过逐像素对比学习,它研究训练像素之间的全局语义关系,引导像素嵌入跨图像类别判别表示,最终提高分割性能。我们的方法产生了有希望的结果,并在各种密集预测任务中显示出巨大的潜力,例如姿势估计 [89, 21] 和身体解析 [88, 20]。
它还带来了新的挑战,特别是在智能数据采样、度量学习损失设计、训练期间的类重新平衡以及多层特征对比方面。鉴于过去几年出现了大量的技术突破,我们预计这些有希望的方向将出现一系列创新。