文章目录
- 前言
- 合合信息
- 多模态大模型与文档图像智能理解
- 文档图像分析识别与理解的技术难题
- 文档图像分析与预处理
- 文档解析与识别
- 版面分析与还原
- 文档信息抽取与理解
- AI安全
- 知识化&存储检索和管理
- 文档图像的分析识别与理解和大模型的关系
- 文档图像大模型的进展
- LayoutLM
- UDOP
- Donut
- BLIP2
- 文档图像大模型的探索
- 文档图像大模型设计思路
- SPTS
- 实验结果
- 展望
前言
近日,2023第十二届中国智能产业高峰论坛(CIIS 2023)在江西南昌顺利举行,本次论坛主要讲解了关于AI大模型、生成式AI、无人系统、智能制造和数字安全等领域的议题。其中令我印象最深刻的就是上海合合信息的丁凯老师讲解的多模态大模型与文档图像智能理解专题论坛的部分了。

合合信息
我们在讲解多模态大模型与文档图像智能理解专题论坛之前先对上海合合信息科技股份有限公司做一个基础的介绍吧。
上海合合信息科技股份有限公司是行业领先的人工智能及大数据科技企业,致力于通过智能文字识别及商业大数据领域的核心技术、C端和B端产品以及行业解决方案为全球企业和个人用户提供创新的数字化、智能化服务。相信大家一定听说过它家的产品——名片全能王、扫描全能王。
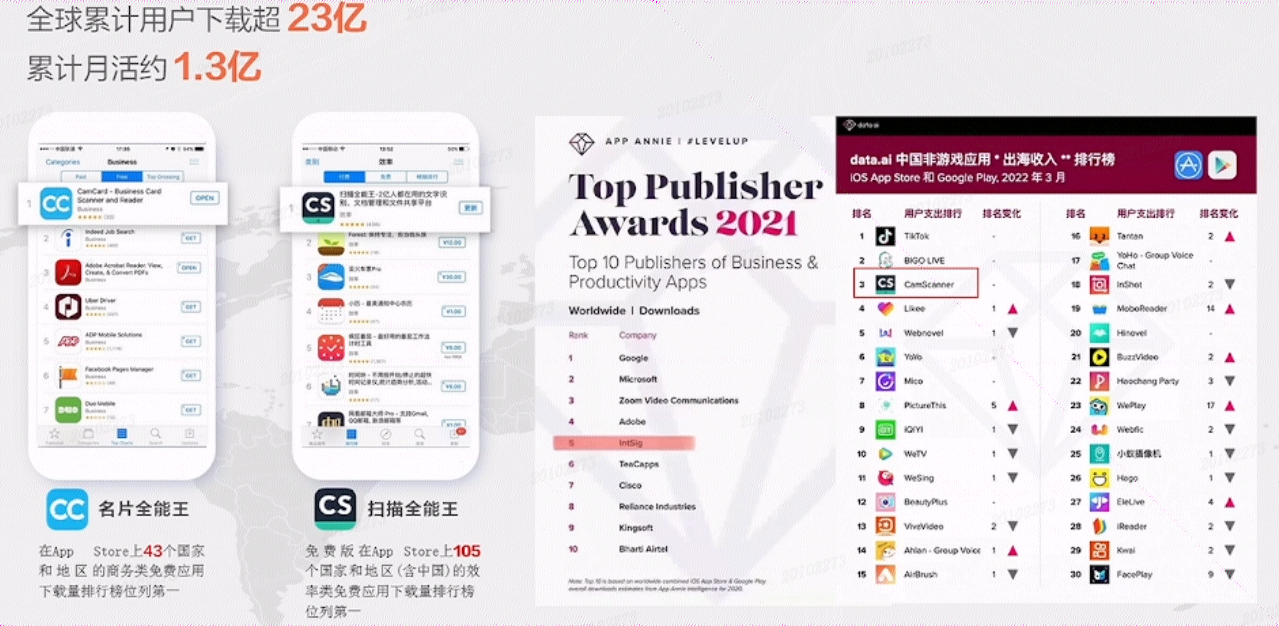
多模态大模型与文档图像智能理解
多模态大模型是指能够同时处理多种类型数据(例如图像、文本、语音等)的强大神经网络模型。它将多个模态的输入数据整合在一起,并通过共享的模型结构进行联合训练和推理。
与传统的深度学习模型通常只针对某一种特定类型的数据进行建模和处理不同的是,多模态大模型则进一步扩展了模型的能力,使其能够同时处理不同类型的数据。
多模态大模型的核心思想是将不同模态的数据进行融合和交互,以实现更全面、准确的任务处理。例如,在图像与文档生成任务中,模型可以同时接受图像和文档输入,并根据两者之间的关联生成相应的输出。这种联合训练和生成的方式可以提供更丰富、多样化的结果。
文档图像分析识别与理解的技术难题
大会上,根据丁老师的讲述,目前文档图像分析识别与理解的技术难题主要体现在以下几个方面:
- 当文档图像质量退化时,会导致文档图像变得模糊不清。这种质量问题与文档图像扫描技术密切相关;
- 根据以下图片案例来看,文字的排布版面非常的复杂,这就给版面分析、文字检测带来了巨大的挑战;
- 在文字识别领域,由于书写的潦草、包括识别的种类非常的多,除了文字、公式还有一些特殊的符号;

基于以上的问题和难题,合合信息将文档图像分析识别与理解的研究主题分成了以下六个模块:
文档图像分析与预处理
主要解决的是文档图像的质量问题,比如一张人眼都无法看清的文档图像在经过切边增强、去摩尔纹、弯曲矫正、图片压缩、PS检测等技术的处理之后变成非常清晰的质量非常高的图像。
文档解析与识别
经过文档图像分析与预处理之后的文档图像会接着来到文档解析与识别模块。我们通过文字识别、表格识别、电子档解析等技术获取到文字信息。
版面分析与还原
我们会把上个步骤拿到的文字信息进行处理,使用元素检测、元素识别、版面还原等技术来识别文档的标题、段落、图像等元素,并还原文档的原始版面结构,以便后续的信息抽取和理解。
文档信息抽取与理解
通过计算机技术,从文档中自动提取出有用信息并进行理解、分类和归纳。文档信息抽取与理解可以帮助人们更加有效地管理和利用大量文档数据,提高工作效率和决策质量。它在数字化档案管理、企业知识管理、搜索引擎、自动化客服等领域具有广泛的应用前景。
AI安全
在文档图像分析识别与理解过程中,通过篡改分类、篡改检测、合成检测、AI生成检测等技术来保证用户的数据隐私和文档图像安全性。
知识化&存储检索和管理
将信息和知识进行有效的组织、存储、检索和管理,在大量的数据和信息中提取有用的知识,并使其易于访问和利用,对于提高工作效率、决策质量和创新能力具有重要意义。

文档图像的分析识别与理解和大模型的关系
丁老师认为文档图像的分析识别与理解和大模型的关系应该是互补的。
举个例子:数据和算力是进行大规模云计算的两个重要因素。随着人工智能和深度学习的发展,大模型的训练需要大量的数据和强大的计算资源。关于全球可用于大模型训练的数据量可能被耗尽的问题,确实有一些机构提出了预测。
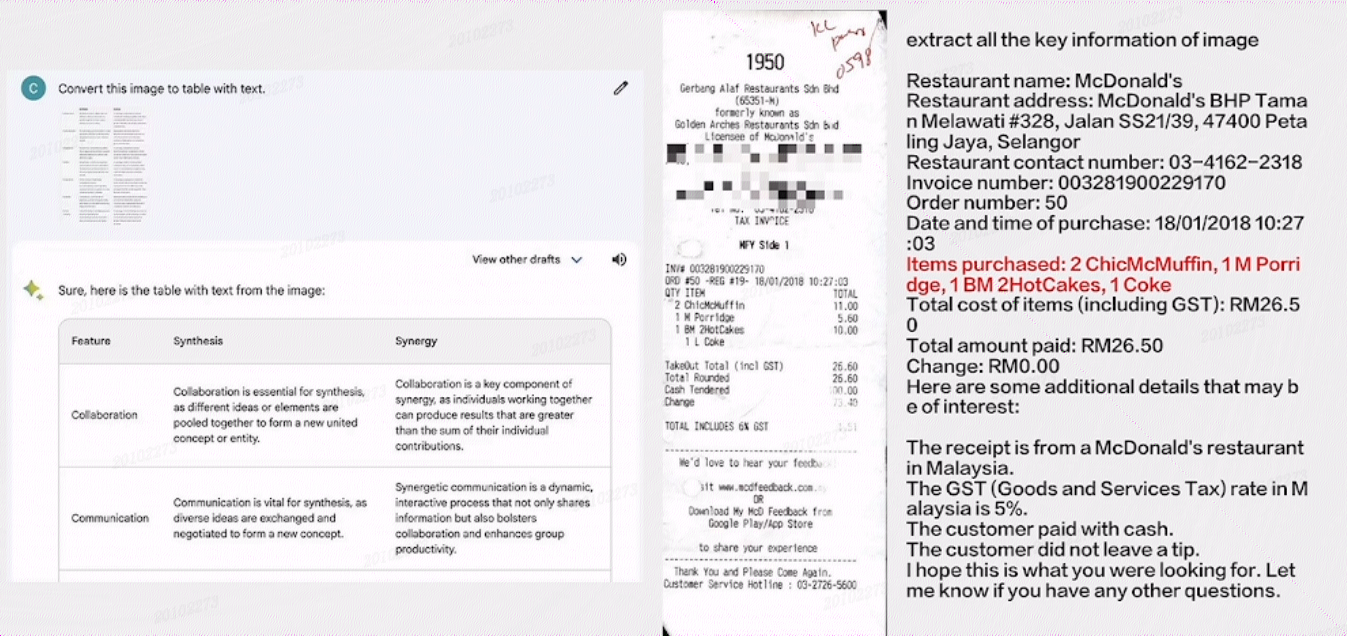
目前,大模型的数据量已经相当庞大,并且很多大型模型厂商已经开始关注电子文档领域。随着大型模型的需求和电子文档的重要性增加,对文档图像扫描和OCR技术的需求也会增加。这对于提供更多训练数据和支持大型模型的计算资源来说,可能是一个新的数据来源和应用领域。
文档图像大模型的进展
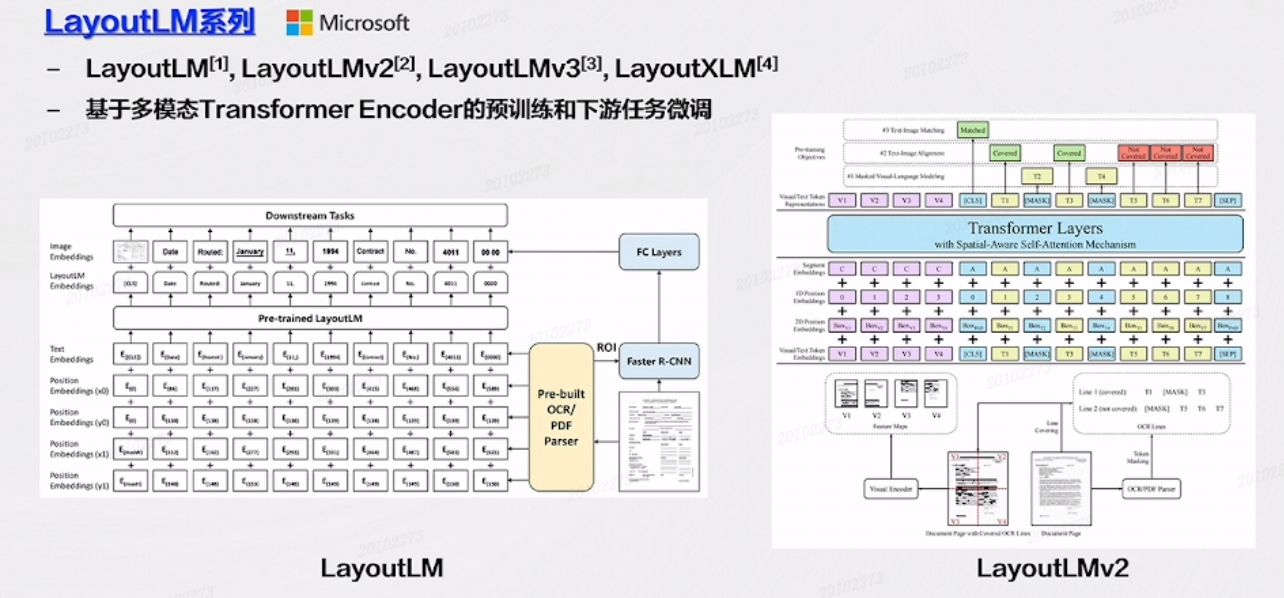
LayoutLM
大家一提到文档图像的大模型,一般都绕不开微软的 LayoutLM 系列大模型。它的工作原理:将文本图像做一次OCR,如果是电子文档直接进行 Parser,将它的文字信息、位置信息、以及后边的图像信息放在一起做一个预训练的模型,然后执行任务。
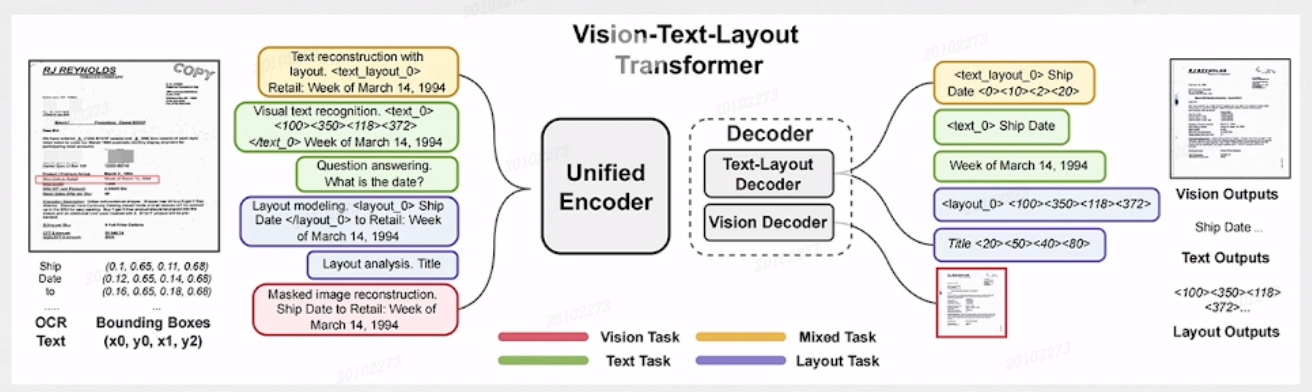
UDOP
微软于2023年推出了文档处理大一统模型 UDOP ,它是端到端的模型。 它采用统一的 Vision-Text-Layout 编码器把文字信息、视觉信息、版面信息进行统一的编码,在解码的时候用 Text-Layouot 和 Vision 解码器分离解码。
Donut
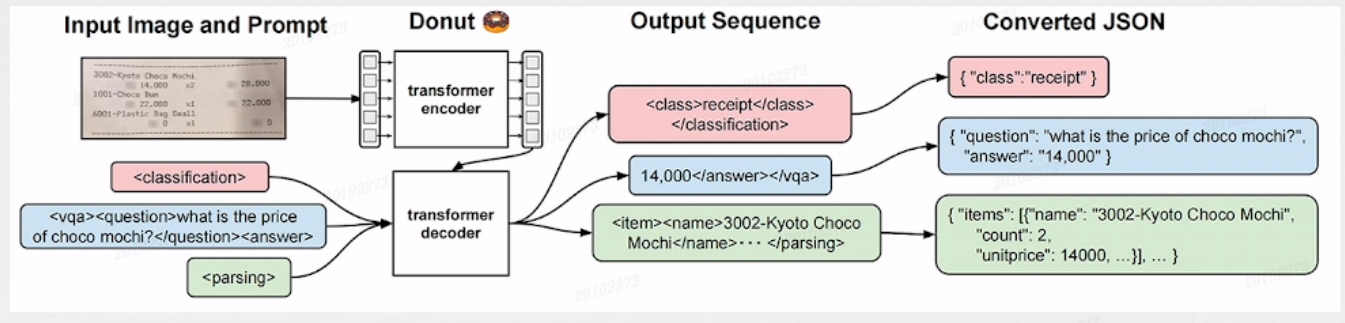
NAVER 在2022年开发了 OCR Free 的文档图像模型Donut,它是无需 OCR 的用于文档理解的 Transformer 模型,即直接处理图像。
BLIP2
多模态模型 BLIP2 将视觉模态和语言模态进行很好的融合,通过 Image Encoder 把图像进行编码,通过 Q-Former 做一个图像模态和文字模态的融合对其,然后再接一个大语言模型。
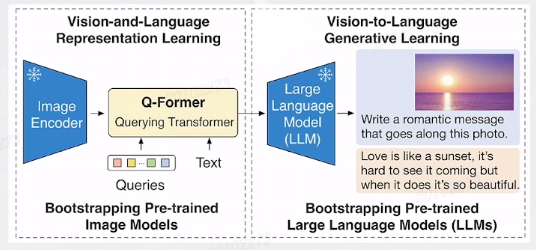
它的特点是不但能理解图像,还可以充分利用大语言模型的理解能力。
合合信息与华南理工大学合作共同研究了文档图像专有大模型 LiLT。LiLT 采用了一种创新性的方法,将视觉和语言模型分开建模,并通过联合建模的方式将它们整合在一起。这种解耦的设计使模型能够更好地处理文档图像中的文本和视觉信息,从而提高了识别和理解的准确性。
为了更好地融合视觉和语言模型,LiLT 引入了双向互补注意力模块(BiCAM)。这一模块的作用是使模型能够在视觉和语言之间进行双向的信息传递和交互,从而更好地捕捉文档图像中不同元素之间的关联性。
LiLT 在多语言小样本和零样本场景下表现出卓越的性能。这意味着即使在数据有限的情况下,该模型仍能够有效地执行文档图像信息抽取任务,展现了其在应对多语言和数据不足情况下的鲁棒性。
文档图像大模型的探索
文档图像大模型设计思路
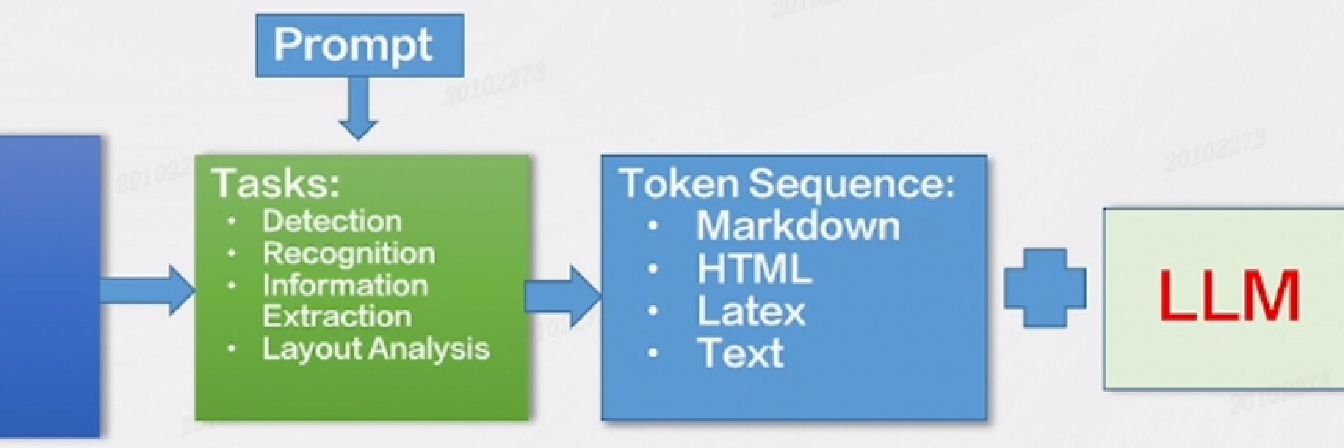
- 将文档图像识别分析的各种任务定义为序列预测的形式
-
- 文本,段落,版面分析,表格,公式等等
- 通过不同的prompt引导模型完成不同的OCR任务
- 支持篇章级的文档图像识别分析,输出Markdown/HTML/Text等标准格式
- 将文档理解相关的工作交给LLM去做
SPTS
SPTS 文档图像大模型主要针对场景文字来做:将端到端检测识别定义为图片到序列的预测任务,采用单点标注指示文本位置,极大地降低了标注成本。无需Rol采样和复杂的后处理操作,真正将检测识别融为一体。

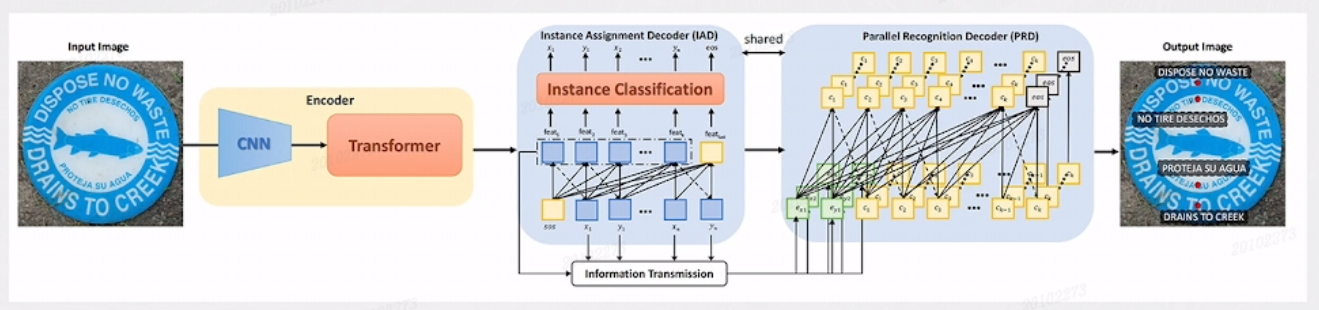
在V2版本中,针对SPTS推理速度较慢的问题,将检测识别解耦为自回归的单点检测和并行的文本识别。IAD根据视觉编码器特征自回归地得到每个文本的单点坐标。PRD根据IAD的单点特征,并行地得到各个文本的识别结果。
经过数轮迭代,基于SPTS的OCR大一统模型(SPTS v3),成功将输入从场景文字拓展到表格、公式、篇章节的文档等。将多种OCR任务定义为序列预测的形式,通过不同的prompt引导模型完成不同的OCR任务,模型沿用SPTS的CNN+TransformerEncoder+Transformer Decoder的图片到序列的结构。

SPTS v3 的任务定义:目前主要关注端到端检测识别、表格结构识别、手写数学公式识别等任务。
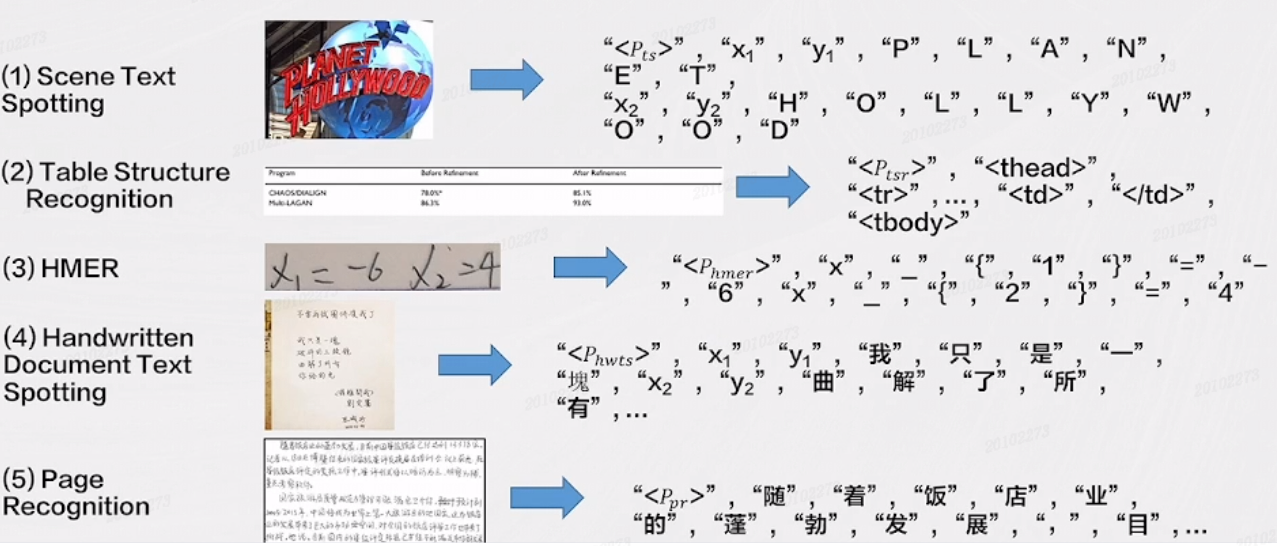
训练平台:A100GPU * 10
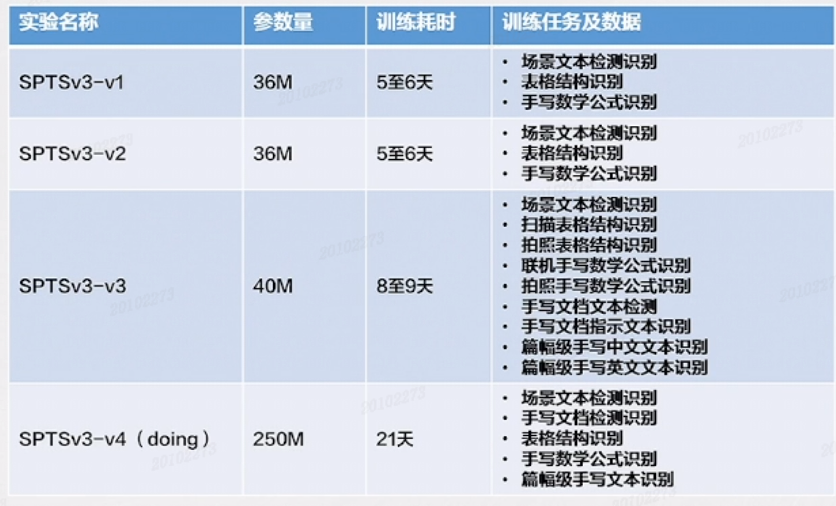
实验结果


展望
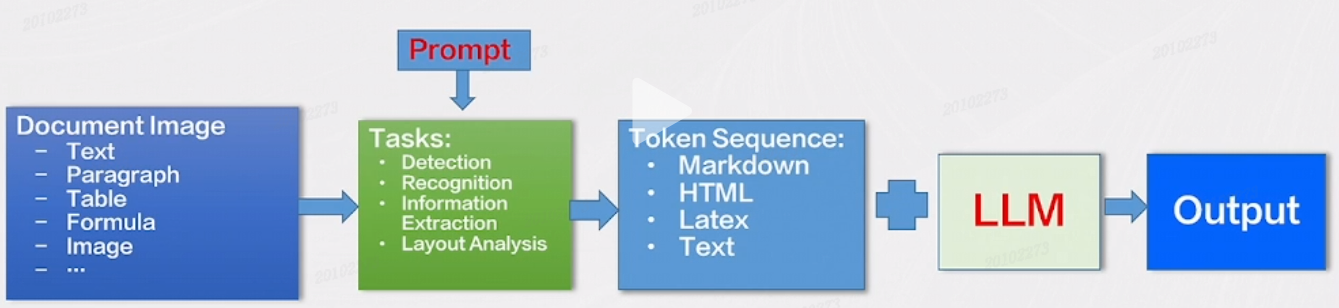
团队期望的是以后在输入的时候不再是一个固定的公式、公式的图片或者是表格的图像,而就是一个文档图像,它里边既有文字又有公式又有表格又有图片。我们通过不同的Prompt 去控制具体提取的是什么,使模型输出 Token Sequence,最后再接大模型,在不同的场景里边去实现多态实际的落地的应用。
合合信息在智能产业中的研究成果具有重要意义。这些成果不仅为各行业提供了实用的解决方案,也为智能产业的发展提供了新的思路和方向。希望它通过不断探索和创新,合合信息有望在智能图像处理及其他领域取得更多突破,推动人工智能技术的应用和智能产业的发展。