目录
- 前言
- 总体设计
- 系统整体结构图
- 系统流程图
- 运行环境
- 爬虫
- 模型训练
- 实际应用
- 模块实现
- 1. 数据准备
- 1)爬虫下载原始图片
- 2)手动筛选图片
- 相关其它博客
- 工程源代码下载
- 其它资料下载

前言
本项目通过爬虫技术获取图片,利用OpenCV库对图像进行处理,识别并切割出人物脸部,形成了一个用于训练的数据集。通过ImageAI进行训练,最终实现了对动漫人物的识别模型。同时,本项目还开发了一个线上Web应用,使得用户可以方便地体验和使用该模型。
首先,项目使用爬虫技术从网络上获取图片。这些图片包含各种动漫人物,其中我们只对人物脸部进行训练,所以我们会对图像进行处理,并最终将这些图像将作为训练数据的来源。
其次,利用OpenCV库对这些图像进行处理,包括人脸检测、图像增强等步骤,以便准确识别并切割出人物脸部。这一步是为了构建一个清晰而准确的数据集,用于模型的训练。
接下来,通过ImageAI进行训练。ImageAI是一个简化图像识别任务的库,它可以方便地用于训练模型,这里用于训练动漫人物的识别模型。
最终,通过项目开发的线上Web应用,用户可以上传动漫图像,系统将使用训练好的模型识别图像中的动漫人物,并返回相应的结果。
总的来说,本项目结合了爬虫、图像处理、深度学习和Web开发技术,旨在提供一个便捷的动漫人物识别服务。这对于动漫爱好者、社交媒体平台等有着广泛的应用前景。
总体设计
本部分包括系统整体结构图和系统流程图。
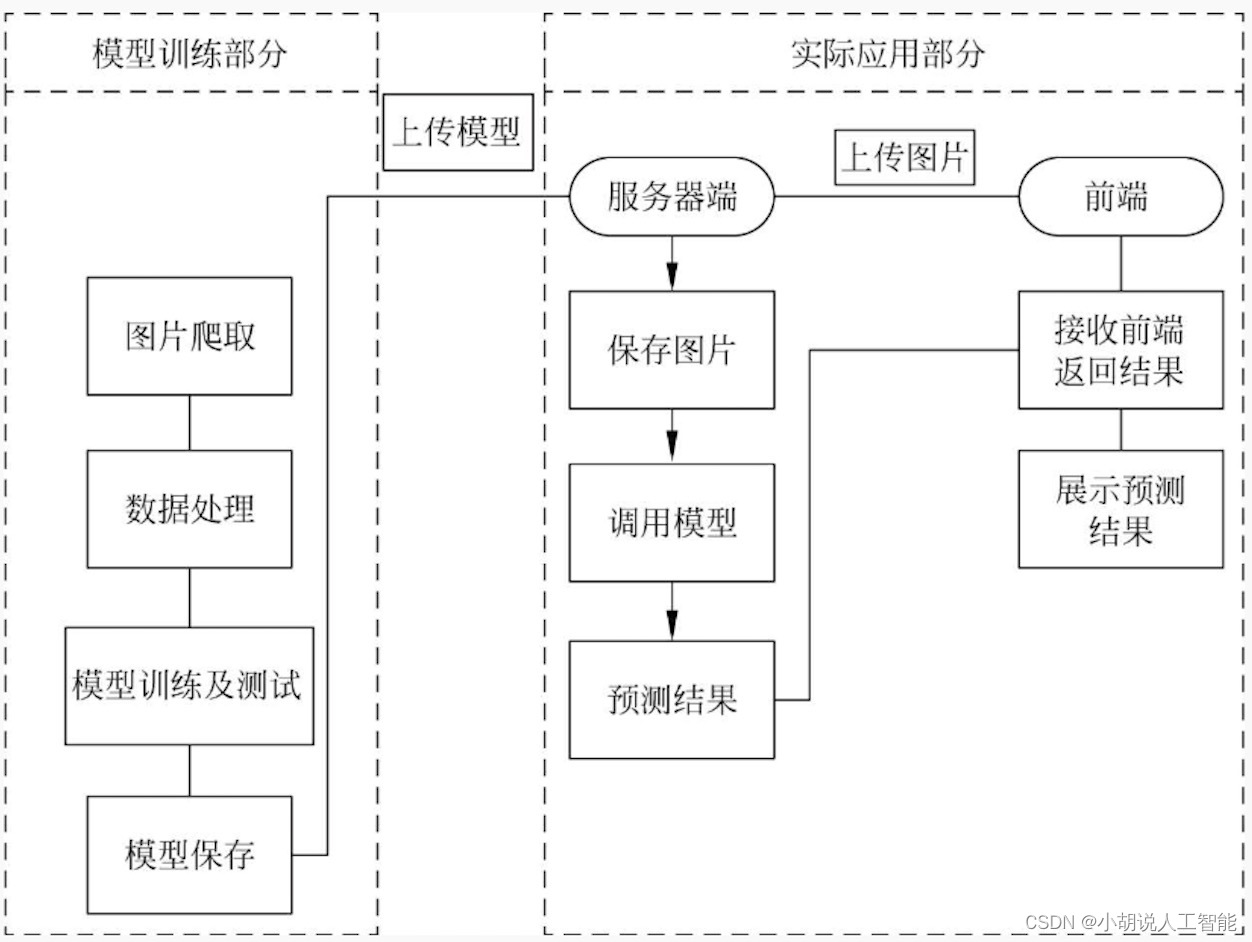
系统整体结构图
系统整体结构如图所示。
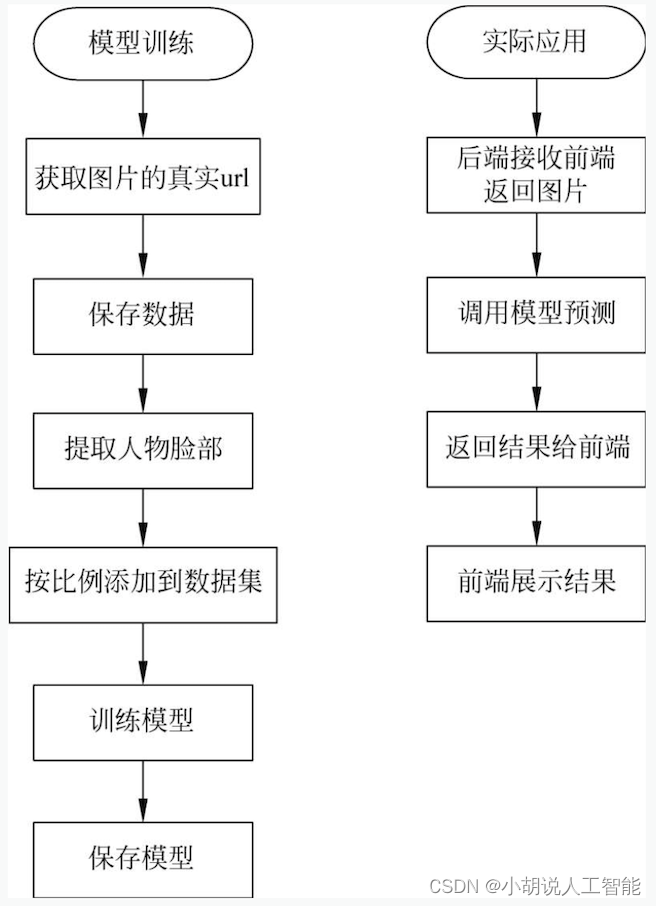
系统流程图
系统流程如图所示。
运行环境
本部分包括爬虫、模型训练及实际应用运行环境。
爬虫
安装Python3.6以上及Selenium3.0.2版本。
详见博客。
模型训练
本部分包括安装依赖、安装ImageAI。
详见博客。
实际应用
实际应用包括前端开发环境和后端环境的搭建。
详见博客。
模块实现
本项目包括4个模块:数据准备、数据处理、模型训练及保存、模型测试,下面分别介绍各模块的功能及相关代码。
1. 数据准备
本项目的数据来自于百度图片,通过爬虫获取。
1)爬虫下载原始图片
下图为下载人物的部分列表。

爬虫可根据列表自动下载指定数量的人物图片存放于指定文件夹,相关代码如下:
python">#phantomjs设置
dcap = dict(DesiredCapabilities.PHANTOMJS)
dcap["phantomjs.page.settings.userAgent"] = (
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.100"
)
#根据关键词爬取并下载图片
#下载基本参数设置,更多参数设置在main()函数处
NAME_LIST = "characters_name_list.txt" #导入需要获取关键字文件,每个关键字一行
MAX_NUM = 60 #每个关键字下载数量
OUTPUT_PATH = "./Raw" #下载图片书保存目录
TIME_OUT = 20 #设置超时
DELAY = 1 #随机下载延迟0~1秒,同样防止被服务器识别出爬虫
#产生随机的header,防止被服务器识别出爬虫
def get_random_headers():
ua = UserAgent().random #产生随机的User-Agent
headers = {
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Proxy-Connection": "keep-alive",
"User-Agent": ua,
"Accept-Encoding": "gzip, deflate, sdch",}
return headers
def get_image_url(keywords, max_number=10000, face_only=False):#获取图像url
def decode_url(url): #解码url
in_table = '0123456789abcdefghijklmnopqrstuvw'
out_table = '7dgjmoru140852vsnkheb963wtqplifca'
translate_table = str.maketrans(in_table, out_table)
mapping = {'_z2C$q': ':', '_z&e3B': '.', 'AzdH3F': '/'}
for k, v in mapping.items():
url = url.replace(k, v)
return url.translate(translate_table)
base_url= "https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592"\
"&lm=7&fp=result&ie=utf-8&oe=utf-8&st=-1"
keywords_str = "&word={}&queryWord={}".format(
quote(keywords), quote(keywords))
query_url = base_url + keywords_str
query_url += "&face={}".format(1 if face_only else 0)
init_url = query_url + "&pn=0&rn=30"
res = requests.get(init_url)
init_json = json.loads(res.text.replace(r"\'", ""), encoding='utf-8', strict=False)
total_num = init_json['listNum']
target_num = min(max_number, total_num)
crawl_num = min(target_num * 2, total_num)
crawled_urls = list()
batch_size = 30
with futures.ThreadPoolExecutor(max_workers=5) as executor:
future_list = list()
def process_batch(batch_no, batch_size): #批处理
image_urls = list()
url = query_url + \
"&pn={}&rn={}".format(batch_no * batch_size, batch_size)
try_time = 0
while True:
try:
response = requests.get(url)
break
except Exception as e:
try_time += 1
if try_time > 3:
print(e)
return image_urls
response.encoding = 'utf-8'
res_json = json.loads(response.text.replace(r"\'", ""), encoding='utf-8', strict=False)
for data in res_json['data']:
if 'objURL' in data.keys():
image_urls.append(decode_url(data['objURL']))
elif'replaceUrl'in data.keys() and len(data['replaceUrl'])== 2:
image_urls.append(data['replaceUrl'][1]['ObjURL'])
return image_urls
for i in range(0, int((crawl_num + batch_size - 1) / batch_size)):
future_list.append(executor.submit(process_batch, i, batch_size))
for future in futures.as_completed(future_list):
if future.exception() is None:
crawled_urls += future.result()
else:
print(future.exception())
return crawled_urls[:min(len(crawled_urls), target_num)]
def get_image_url(keywords, max_number=10000, face_only=False):
def decode_url(url): #解码
in_table = '0123456789abcdefghijklmnopqrstuvw'
out_table = '7dgjmoru140852vsnkheb963wtqplifca'
translate_table = str.maketrans(in_table, out_table)
mapping = {'_z2C$q': ':', '_z&e3B': '.', 'AzdH3F': '/'}
for k, v in mapping.items():
url = url.replace(k, v)
return url.translate(translate_table)
base_url = "https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592"\
"&lm=7&fp=result&ie=utf-8&oe=utf-8&st=-1"
keywords_str = "&word={}&queryWord={}".format(
quote(keywords), quote(keywords))
query_url = base_url + keywords_str
query_url += "&face={}".format(1 if face_only else 0)
init_url = query_url + "&pn=0&rn=30"
res = requests.get(init_url)
init_json = json.loads(res.text.replace(r"\'", ""), encoding='utf-8', strict=False)
total_num = init_json['listNum']
target_num = min(max_number, total_num)
crawl_num = min(target_num * 2, total_num)
crawled_urls = list()
batch_size = 30
with futures.ThreadPoolExecutor(max_workers=5) as executor:
future_list = list()
def process_batch(batch_no, batch_size):
image_urls = list()
url = query_url + \
"&pn={}&rn={}".format(batch_no * batch_size, batch_size)
try_time = 0
while True:
try:
response = requests.get(url)
break
except Exception as e:
try_time += 1
if try_time > 3:
print(e)
return image_urls
response.encoding = 'utf-8'
res_json = json.loads(response.text.replace(r"\'", ""), encoding='utf-8', strict=False)
for data in res_json['data']:
if 'objURL' in data.keys():
image_urls.append(decode_url(data['objURL']))
elif'replaceUrl' in data.keys() and len(data['replaceUrl']) == 2:
image_urls.append(data['replaceUrl'][1]['ObjURL'])
return image_urls
for i in range(0, int((crawl_num + batch_size - 1) / batch_size)):
future_list.append(executor.submit(process_batch, i, batch_size))
for future in futures.as_completed(future_list):
if future.exception() is None:
crawled_urls += future.result()
else:
print(future.exception())
return crawled_urls[:min(len(crawled_urls), target_num)]
#main函数
def main(list_file, output="./Raw", max_number=100, threads=50, timeout=20, time_delay=3, face_only=True,
browser="phantomjs", quiet=False, file_prefix="img"):
with open(list_file, encoding="utf-8") as keywords_list:
for keywords in keywords_list:
keywords = keywords.rstrip() #去除换行符
if keywords == "": #跳过空行
continue
if os.path.exists(os.path.join(output, keywords)): #查看是否已经下载
print("[warn: ] [{}] is already downloaded, downloader will skip [{}]".format(keywords, keywords))
continue
crawled_urls = crawler.crawl_image_urls(keywords, max_number=max_number, face_only=face_only,
browser=browser, quiet=quiet)
download_images(image_urls=crawled_urls, dst_dir=output, keywords=keywords,
concurrency=threads, timeout=timeout,time_delay=time_delay, file_prefix=file_prefix)
img_count = len(os.listdir(os.path.join(output, keywords)))
print("[{}]: get {} image(s)".format(keywords, img_count))
def download_image(image_url, dst_dir, file_name, timeout=20, time_delay=1):
time.sleep(random.randint(0, time_delay)) #暂停0~time_delay的整数秒
response = None
file_path = os.path.join(dst_dir, file_name)
try_times = 0
while True:
try:
try_times += 1
response = requests.get(
image_url, headers=get_random_headers(), timeout=timeout)
with open(file_path, 'wb') as f:
f.write(response.content)
response.close()
file_type = imghdr.what(file_path)
if file_type in ["jpg", "jpeg", "png", "bmp"]:
new_file_name = "{}.{}".format(file_name, file_type)
new_file_path = os.path.join(dst_dir, new_file_name)
shutil.move(file_path, new_file_path)
print("[OK:] {} {}".format(new_file_name, image_url))
else:
os.remove(file_path)
print("[Err:] file type err or not exists {}".format(image_url))
break
except Exception as e:
if try_times < 3:
continue
if response:
response.close()
print("[Fail:] {} {}".format(image_url, e.args))
break
def download_images(image_urls, dst_dir, keywords, file_prefix="img", concurrency=50, timeout=20, time_delay=1):
with concurrent.futures.ThreadPoolExecutor(max_workers=concurrency) as executor:
future_list = list()
count = 0
dst_dir = os.path.join(dst_dir, keywords)
if not os.path.exists(dst_dir):
os.makedirs(dst_dir)
for image_url in image_urls:
file_name = file_prefix + "_" + "%04d" % count
future_list.append(executor.submit(
download_image, image_url, dst_dir, file_name, timeout, time_delay))
count += 1
concurrent.futures.wait(future_list, timeout=180)
结果如图所示。

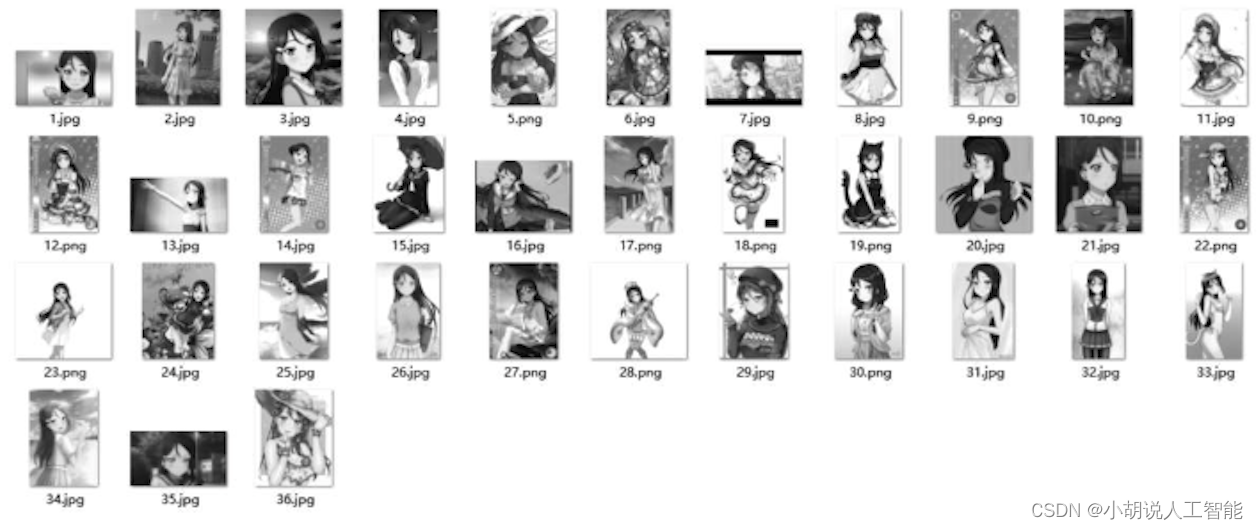
2)手动筛选图片
部分人物的名称、现实事物或人物有重名现象,加上一些图片质量不佳,需要人为剔除,手动筛选,如图所示。
相关其它博客
基于opencv+ImageAI+tensorflow的智能动漫人物识别系统——深度学习算法应用(含python、JS、模型源码)+数据集(一)
基于opencv+ImageAI+tensorflow的智能动漫人物识别系统——深度学习算法应用(含python、JS、模型源码)+数据集(三)
基于opencv+ImageAI+tensorflow的智能动漫人物识别系统——深度学习算法应用(含python、JS、模型源码)+数据集(四)
工程源代码下载
详见本人博客资源下载页
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。