1.之前只能做一些图像预测,我有个大胆的想法,如果神经网络正向就是预测图片的类别,如果我只有一个类别那就可以进行生成图片,专业术语叫做gan对抗网络
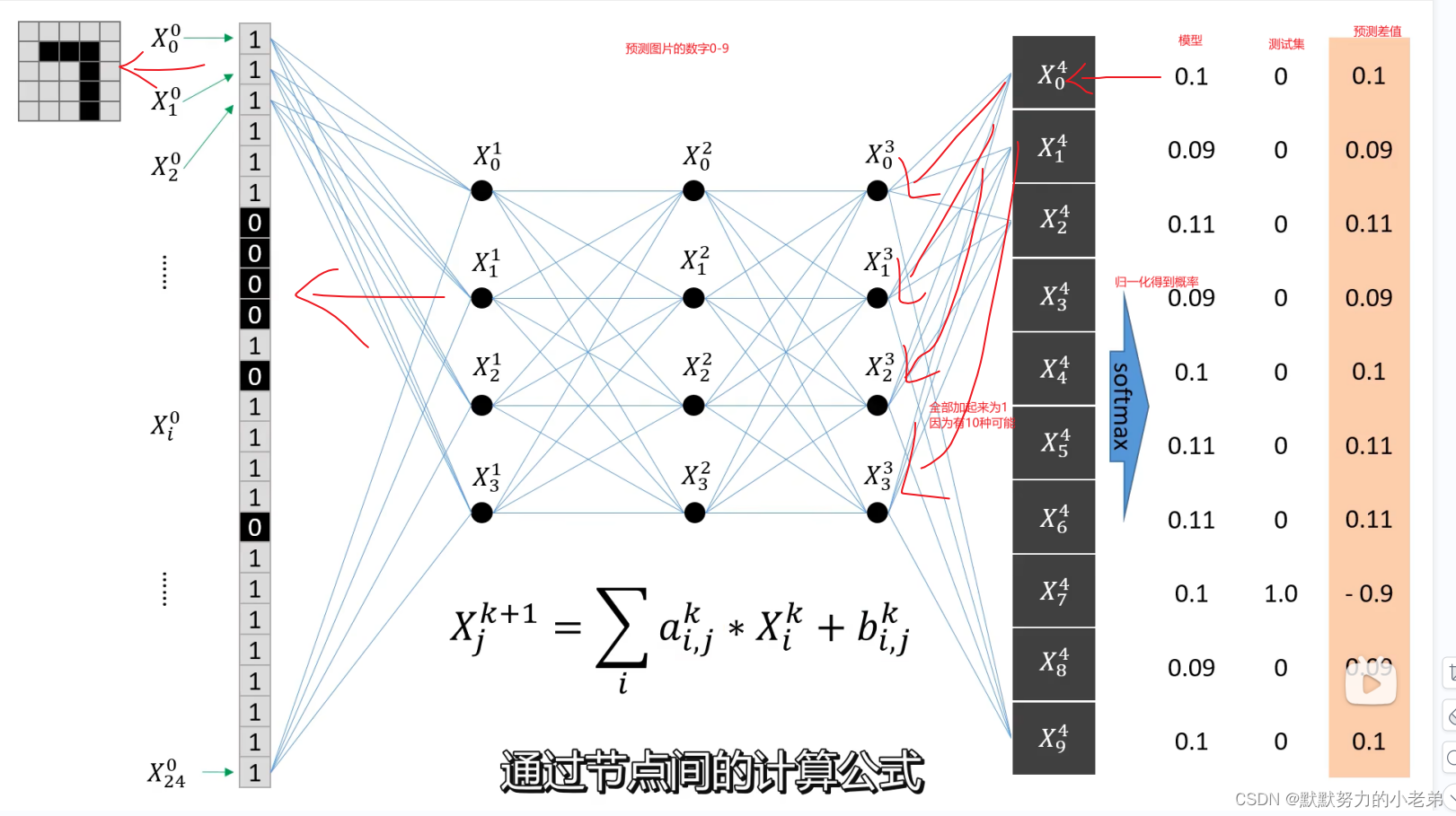
2.训练代码
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
import torchvision.datasets as dset
import matplotlib.pyplot as plt
import os
# 设置环境变量
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
# 定义生成器模型
class Generator(nn.Module):
def __init__(self, input_dim=100, output_dim=784):
super(Generator, self).__init__()
self.fc1 = nn.Linear(input_dim, 256)
self.fc2 = nn.Linear(256, 512)
self.fc3 = nn.Linear(512, 1024)
self.fc4 = nn.Linear(1024, output_dim)
self.relu = nn.ReLU()
self.tanh = nn.Tanh()
def forward(self, x):
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.relu(self.fc3(x))
x = self.tanh(self.fc4(x))
return x
# 定义判别器模型
class Discriminator(nn.Module):
def __init__(self, input_dim=784, output_dim=1):
super(Discriminator, self).__init__()
self.fc1 = nn.Linear(input_dim, 1024)
self.fc2 = nn.Linear(1024, 512)
self.fc3 = nn.Linear(512, 256)
self.fc4 = nn.Linear(256, output_dim)
self.relu = nn.ReLU()
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.relu(self.fc3(x))
x = self.sigmoid(self.fc4(x))
return x
# 加载 MNIST 手写数字图片数据集
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
dataroot = "path_to_your_mnist_dataset" # 替换为 MNIST 数据集的路径
dataset = dset.MNIST(root=dataroot, train=True, transform=transform, download=True)
dataloader = torch.utils.data.DataLoader(dataset, batch_size=128, shuffle=True)
# 创建生成器和判别器实例
input_dim = 100
output_dim = 784
generator = Generator(input_dim, output_dim)
discriminator = Discriminator(output_dim)
# 定义优化器和损失函数
lr = 0.0002
beta1 = 0.5
optimizer_g = optim.Adam(generator.parameters(), lr=lr, betas=(beta1, 0.999))
optimizer_d = optim.Adam(discriminator.parameters(), lr=lr, betas=(beta1, 0.999))
criterion = nn.BCELoss()
# 训练 GAN 模型
num_epochs = 50
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("Device:", device)
generator.to(device)
discriminator.to(device)
for epoch in range(num_epochs):
for i, data in enumerate(dataloader, 0):
real_images, _ = data
real_images = real_images.to(device)
batch_size = real_images.size(0) # 获取批次样本数量
# 训练判别器
optimizer_d.zero_grad()
real_labels = torch.full((batch_size, 1), 1.0, device=device)
fake_labels = torch.full((batch_size, 1), 0.0, device=device)
noise = torch.randn(batch_size, input_dim, device=device)
fake_images = generator(noise)
real_outputs = discriminator(real_images.view(batch_size, -1))
fake_outputs = discriminator(fake_images.detach())
d_loss_real = criterion(real_outputs, real_labels)
d_loss_fake = criterion(fake_outputs, fake_labels)
d_loss = d_loss_real + d_loss_fake
d_loss.backward()
optimizer_d.step()
# 训练生成器
optimizer_g.zero_grad()
noise = torch.randn(batch_size, input_dim, device=device)
fake_images = generator(noise)
fake_outputs = discriminator(fake_images)
g_loss = criterion(fake_outputs, real_labels)
g_loss.backward()
optimizer_g.step()
# 输出训练信息
if i % 100 == 0:
print("[Epoch %d/%d] [Batch %d/%d] [D loss: %.4f] [G loss: %.4f]"
% (epoch, num_epochs, i, len(dataloader), d_loss.item(), g_loss.item()))
# 保存生成器的权重和图片示例
if epoch % 10 == 0:
with torch.no_grad():
noise = torch.randn(64, input_dim, device=device)
fake_images = generator(noise).view(64, 1, 28, 28).cpu().numpy()
fig, axes = plt.subplots(nrows=8, ncols=8, figsize=(12, 12), sharex=True, sharey=True)
for i, ax in enumerate(axes.flatten()):
ax.imshow(fake_images[i][0], cmap='gray')
ax.axis('off')
plt.subplots_adjust(wspace=0.05, hspace=0.05)
plt.savefig("epoch_%d.png" % epoch)
plt.close()
torch.save(generator.state_dict(), "generator_epoch_%d.pth" % epoch)
3.测试模型的代码
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision.utils import save_image
# 定义生成器模型
class Generator(nn.Module):
def __init__(self, input_dim, output_dim):
super(Generator, self).__init__()
self.fc1 = nn.Linear(input_dim, 256)
self.fc2 = nn.Linear(256, 512)
self.fc3 = nn.Linear(512, 1024)
self.fc4 = nn.Linear(1024, output_dim)
def forward(self, x):
x = F.leaky_relu(self.fc1(x), 0.2)
x = F.leaky_relu(self.fc2(x), 0.2)
x = F.leaky_relu(self.fc3(x), 0.2)
x = torch.tanh(self.fc4(x))
return x
# 创建生成器模型
generator = Generator(input_dim=100, output_dim=784)
# 加载预训练权重
generator_weights = torch.load("generator_epoch_40.pth", map_location=torch.device('cpu'))
# 将权重加载到生成器模型
generator.load_state_dict(generator_weights)
# 生成随机噪声
noise = torch.randn(1, 100)
# 生成图像
fake_image = generator(noise).view(1, 1, 28, 28)
# 保存生成的图片
save_image(fake_image, "generated_image.png", normalize=False)
#测试结果,由于我的训练集是数字的,所以会生成各种各样的数字,下面明显的是1

#应该也是1

#再次运行,我也看不出来,不过只要我训练只有一个种类的问题就可以生成这个种类的图像

#搞定黑白图,那彩色图应该距离不远了,我需要改进的是把对抗网络的代码改为训练一个种类的图形,不过我感觉这种图形具有随机性,虽然通过训练我们得到了所有图像他们的规律,但是如果需要正常点的图片还是挺难的,就像是上面这张人都不一定知道他是什么东西(在没有颜色的情况下)总结就是精度不够,而且随机性太强了,现在普遍图片AI生成工具具有这个缺点(生成的物体可能会扭曲,挺阴间的),而且生成的图片速度慢,如果谁比较受益那一定是老黄(英伟达)哈哈哈
//比如下面这个图片生成视频的网站
https://app.runwayml.com/login
#每一帧看起来都没有问题,就是连起来变成视频不自然,如果有改进方法的话那可能需要引入重力/加速度/光处理 等等物理公式,来让图片更自然…