Abstarct
识别不太显著的特征是模型压缩的关键。然而,在革命性的注意力机制中却没有对其进行研究。在这项工作中,我们提出了一种新的基于归一化的注意力模块(NAM),它抑制了不太显著的权重。它对注意力模块应用了权重稀疏性惩罚,从而使它们在保持类似性能的同时具有更高的计算效率。与Resnet和Mobilenet上的其他三种注意力机制的比较表明,我们的方法具有更高的准确性。
Introduction
注意机制是近年来研究的热点之一 (Wang et al.[2017], Hu et al. [2018], Park et al. [2018], Woo et al. [2018], Gao et al. [2019]).)。它有助于深度神经网络抑制不太显著的像素或通道。先前的许多研究都集中在通过注意力操作捕捉显著特征上(Zhang et al. [2020], Misra et al. [2021])。这些方法成功地利用了来自不同维度特征的相互信息。然而,它们缺乏对权重的贡献因素的考虑,这能够进一步抑制不重要的通道或像素。受Liu et al. [2017]的启发,我们旨在利用权重的贡献因素来改善注意力机制。我们使用批量归一化的比例因子,该比例因子使用标准偏差来表示权重的重要性。这可以避免添加SE、BAM和CBAM中使用的完全连接层和卷积层。因此,我们提出了一种有效的注意力机制——基于归一化的注意力模块(NAM)。
Related work
许多先前的工作试图通过抑制不重要的权重来提高神经网络的性能。挤压和激励网络(SENet)(Hu et al[2018])将空间信息集成到通道特征响应中,并使用两个多层感知器(MLP)层计算相应的注意力。后来,瓶颈注意力模块(BAM)(Park et al. [2018]) b并行构建了分离的空间和通道子模块,它们可以嵌入到每个瓶颈块中。卷积块注意力模块(CBAM) (Woo et al. [2018]) 提供了一种按顺序嵌入通道和空间注意力子模块的解决方案,为了避免忽视跨维度交互,三重注意力模块(TAM)) (Misra et al. [2021]) 通过旋转特征图来考虑维度相关性。然而,这些工作忽略了来自训练的调谐权重的信息。因此,我们的目标是通过利用训练的模型权重的方差测量来突出显著特征。
Methodology
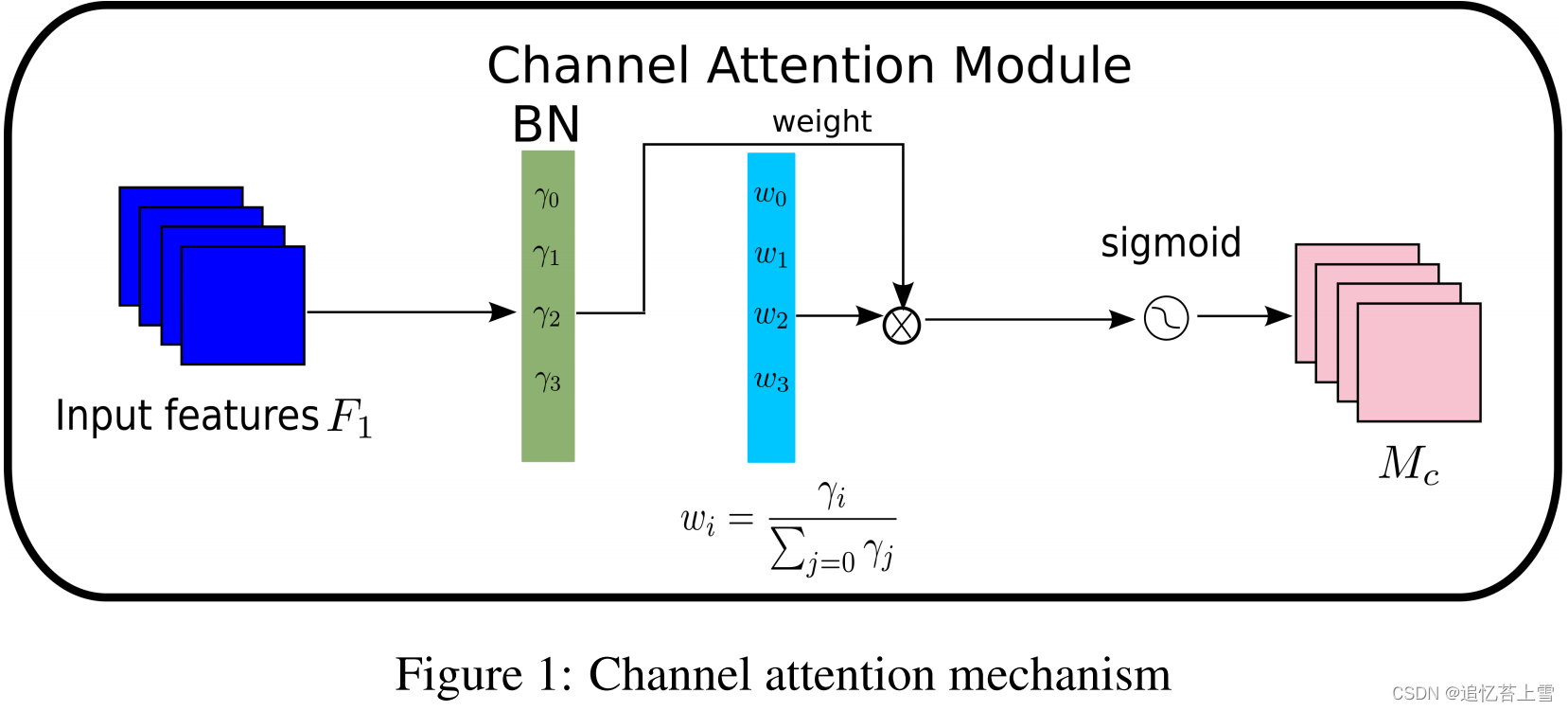
我们提出了NAM作为一种高效和轻量级的注意机制。我们采用了CBAM的模块集成(Woo et al[2018]),并重新设计了通道和空间注意力子模块。然后,在每个网络块的末端嵌入一个NAM模块。对于残差网络,它嵌入在残差结构的末端。对于通道注意力子模块,我们使用批量归一化(BN)的比例因子(Ioffe and Szegedy [2015]),如公式(1)所示。比例因子测量信道的方差并指示它们的重要性。
(1)
其中和
分别为小批量
的平均值和标准偏差;γ和β是可训练的仿射变换参数(尺度和偏移)(Ioffe and Szegedy [2015])。通道注意力子模块如图1和方程(2)所示,其中
表示输出特征。γ是每个通道的比例因子,权重为
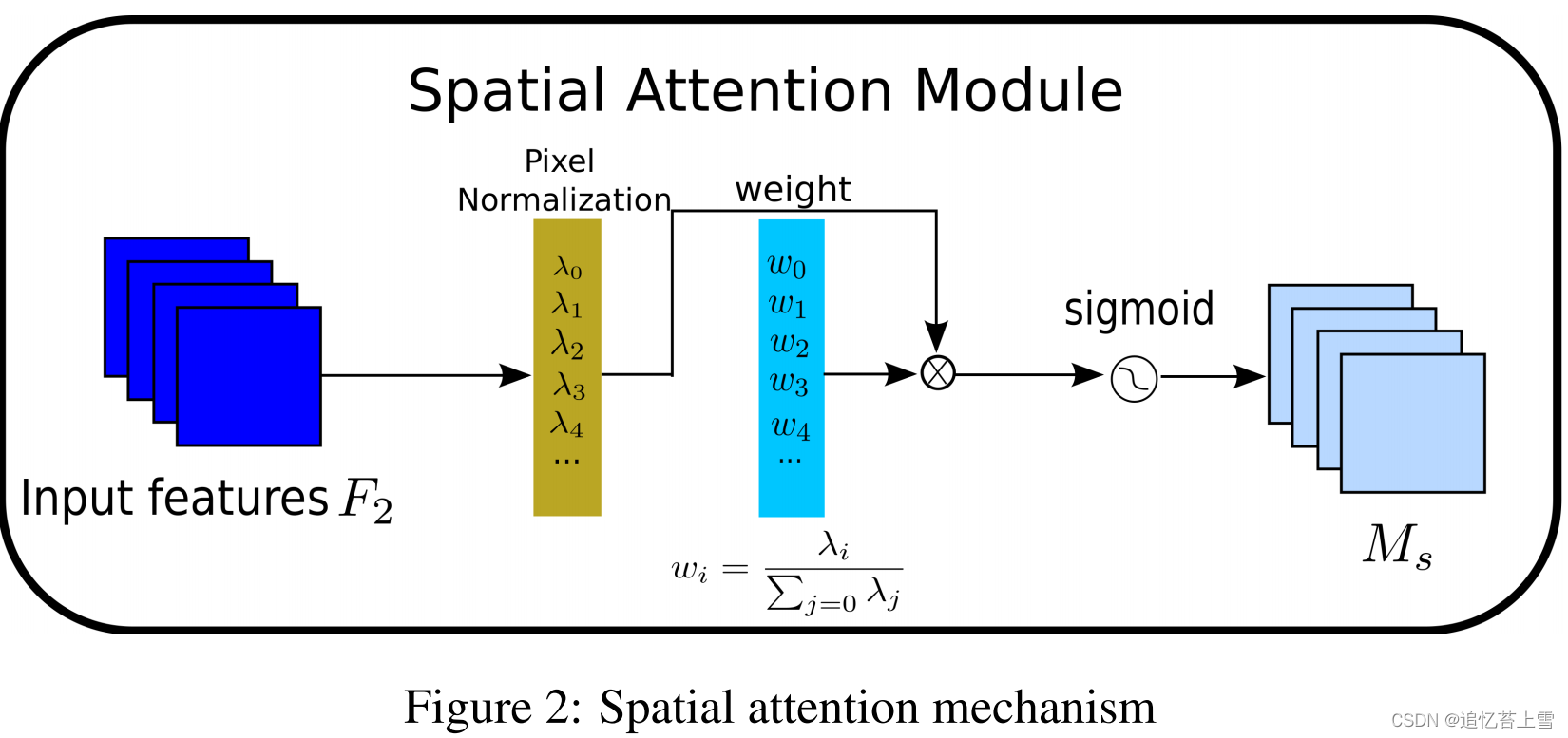
。我们还将BN的比例因子应用于空间维度,以测量像素的重要性。我们将其命名为像素归一化。相应的空间注意力子模块如图2和方程(3)所示,其中输出表示为
。
是比例因子,权重为
。为了抑制不太显著的权重,我们将正则化项添加到损失函数中,如方程(4)所示(Liu et al[2017]),其
表示输入,γ是输出;表示网络权重;
是损失函数;
是
范数罚函数;
是平衡
和
的惩罚。
(2)
(3)
(4)
Experiment
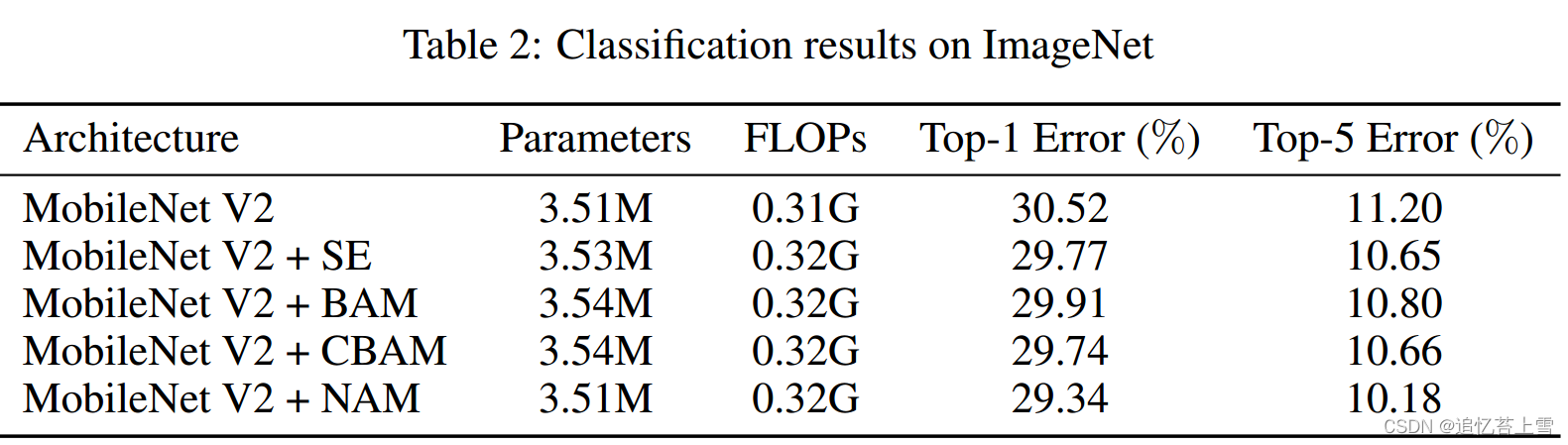
在本节中,我们比较了NAM与SE、BAM、CBAM和TAM在ResNet和MobileNet中的性能。我们在一个集群上使用四个Nvidia Tesla V100 GPU来评估每种方法。我们首先在CIFAR-100上运行ResNet50(Krizhevsky等人[2009]),并使用与CBAM相同的预处理和训练配置(Woo等人[2018]),p为0.0001。表1中的比较表明,单独使用通道或空间注意力的NAM优于其他四种注意力机制。然后,我们在ImageNet上运行MobileNet(Deng等人[2009]),因为它是图像分类基准的标准数据集之一。我们将p设置为0.001,其余配置与CBAM相同。表2中的比较表明,信道和空间注意力相结合的NAM优于其他三种计算复杂度相似的NAM。

Conclusion
我们提出了一个NAM模块,该模块通过抑制不太显著的特征来提高效率。我们的实验表明,NAM在ResNet和MobileNet上都提供了效率增益。我们正在对NAM在积分变化和超参数调整方面的性能进行详细分析。我们还计划利用不同的模型压缩技术对 NAM 进行优化,以提高其效率。未来,我们将研究它对其他深度学习架构和应用的影响。
Code
import torch.nn as nn
import torch
from torch.nn import functional as F
class Channel_Att(nn.Module):
def __init__(self, channels, t=16):
super(Channel_Att, self).__init__()
self.channels = channels
self.bn2 = nn.BatchNorm2d(self.channels, affine=True)
def forward(self, x):
residual = x
x = self.bn2(x)
weight_bn = self.bn2.weight.data.abs() / torch.sum(self.bn2.weight.data.abs())
x = x.permute(0, 2, 3, 1).contiguous()
x = torch.mul(weight_bn, x)
x = x.permute(0, 3, 1, 2).contiguous()
x = torch.sigmoid(x) * residual #
return x
class Att(nn.Module):
def __init__(self, channels,shape, out_channels=None, no_spatial=True):
super(Att, self).__init__()
self.Channel_Att = Channel_Att(channels)
def forward(self, x):
x_out1=self.Channel_Att(x)
return x_out1 

![TeXiFy IDEA 编译后文献引用为 “[?]“](https://img-blog.csdnimg.cn/direct/464f404a023f4f89a3a2929916f8e404.png)

