目录
一、前言
二、实验目的
三、实验内容
四、实验过程
一、前言
编程语言:Python,编程软件:vscode或pycharm,必备的第三方库:OpenCV,numpy,matplotlib,os等等。
关于OpenCV,numpy,matplotlib,os等第三方库的下载方式如下:
第一步,按住【Windows】和【R】调出运行界面,输入【cmd】,回车打开命令行。
第二步,输入以下安装命令(可以先升级一下pip指令)。
pip升级指令:
python -m pip install --upgrade pip
opencv库的清华源下载:
pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple
numpy库的清华源下载:
pip install numpy -i https://pypi.tuna.tsinghua.edu.cn/simple
matplotlib库的清华源下载:
pip install matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple
os库的清华源下载:
pip install os -i https://pypi.tuna.tsinghua.edu.cn/simple
二、实验目的
1.了解不同图像缩放算法;
2.基于公用图像处理函式库完成图片、视频缩小及放大;
3.根据图像缩放算法,自行撰写代码完成图像及视频数据的缩小及放大;
4.比较及分析公用函式库及自行撰写函式的效能。
三、实验内容
1.任选彩色图片、视频,进行缩小及放大
(1)使用OpenCV函数
(2)不使用OpenCV函数
- Nearest-Neighbor interpolation
- Bi-linear interpolation
2.在彩色图、视频上任意选取区域執行不同的放大方式,结果如下图
(1)使用OpenCV函数
(2)不使用OpenCV函数
- Nearest-Neighbor interpolation
- Bi-linear interpolation
四、实验过程
(1)基于OpenCV的图像和视频缩放:
图像代码如下:
python">import cv2
import matplotlib.pyplot as plt
# 读取原始图像
img_origin = cv2.imread(r"D:\Image\img1.jpg")
# 获取图像的高度和宽度
height, width = img_origin.shape[:2]
# 放大图像
img_amplify = cv2.resize(img_origin, None, fx = 1.25, fy = 1.0, interpolation = cv2.INTER_AREA)
# 缩小图像
img_reduce = cv2.resize(img_origin, None, fx = 0.75, fy = 1.0, interpolation = cv2.INTER_AREA)
# 创建一个大小为(10, 10)的图形
plt.figure(figsize=(10, 10))
# 在第1行第1列的位置创建子图,设置坐标轴可见,设置标题为"origin"
plt.subplot(1, 3, 1), plt.axis('on'), plt.title("origin")
# 显示原始图像
plt.imshow(cv2.cvtColor(img_origin, cv2.COLOR_BGR2RGB))
# 在第1行第2列的位置创建子图,设置坐标轴可见,设置标题为"amplify: fx = 1.25, fy = 1.0"
plt.subplot(1, 3, 2), plt.axis('on'), plt.title("amplify: fx = 1.25, fy = 1.0")
# 显示放大后的图像
plt.imshow(cv2.cvtColor(img_amplify, cv2.COLOR_BGR2RGB))
# 在第1行第3列的位置创建子图,设置坐标轴可见,设置标题为"reduce: fx = 0.75, fy = 1.0"
plt.subplot(1, 3, 3), plt.axis('on'), plt.title("reduce: fx = 0.75, fy = 1.0")
# 显示缩小后的图像
plt.imshow(cv2.cvtColor(img_reduce, cv2.COLOR_BGR2RGB))
# 调整子图布局
plt.tight_layout()
# 显示图形
plt.show()
# 保存图像
retval = cv2.imwrite(r"D:\Image\image_lab2\img_amplify.jpg", img_amplify)
retval = cv2.imwrite(r"D:\Image\image_lab2\img_reduce.jpg", img_reduce)代码运行结果:

视频代码如下:
python">import cv2
import os
cap = cv2.VideoCapture(r"D:\Image\video1.mp4")
currentframe = 0
# 循环读取视频帧并保存为图片
while (True):
ret, frame = cap.read()
if ret:
name = str(currentframe)
cv2.imwrite(r"D:\Image\image_lab2\video_img\%s.jpg"%name, frame)
currentframe += 1
else:
break
# 释放视频对象
cap.release()
video_path = r"D:\Image\image_lab2\video_img"
# 获取视频文件夹中的所有文件
img_files = os.listdir(video_path)
# 统计图片文件数量
img_count = len(img_files)
# 设定视频编解码器
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
# 设定图片大小放大后的目标尺寸
img_size_amplify = (1280, 1280)
# 设定图片大小缩小后的目标尺寸
img_size_reduce = (720, 720)
# 视频保存路径(放大版本)
video_save_amplify = r"D:\Image\image_lab2\video_amplify.mp4"
# 视频保存路径(缩小版本)
video_save_reduce = r"D:\Image\image_lab2\video_reduce.mp4"
# 创建放大版本的视频写入对象
video_writer_amplify = cv2.VideoWriter(video_save_amplify, fourcc, 60, img_size_amplify)
# 创建缩小版本的视频写入对象
video_writer_reduce = cv2.VideoWriter(video_save_reduce, fourcc, 60, img_size_reduce)
print("视频放大及缩小开始")
for i in range(0, img_count):
# 设定图片文件路径
img_path = video_path + "/" + str(i) + ".jpg"
# 读取图片
img = cv2.imread(img_path, cv2.IMREAD_COLOR)
# 若读取失败则跳过本次循环
if img is None:
continue
# 图片放大
img_amplify = cv2.resize(img, img_size_amplify)
# 图片缩小
img_reduce = cv2.resize(img, img_size_reduce)
# 将放大后的图片写入放大版本的视频
video_writer_amplify.write(img_amplify)
# 将缩小后的图片写入缩小版本的视频
video_writer_reduce.write(img_reduce)
print(f"第{i}张图片合成完成")
print("视频放大及缩小完成")基于最近邻插值和双线性插值的图像和视频缩放:
将最近邻插值和双线性插值编写成函数文件,命名为【Nearest_Bilinear】,代码如下:
python">import numpy as np
def Nearest(img, height, width, channels):
# 创建一个与给定高度、宽度和通道数相同的零数组
img_nearest = np.zeros(shape=(height, width, channels), dtype=np.uint8)
# 遍历每个像素点
for i in range(height):
for j in range(width):
# 计算在给定高度和宽度下对应的img的行和列
row = (i / height) * img.shape[0]
col = (j / width) * img.shape[1]
# 取最近的整数行和列
row_near = round(row)
col_near = round(col)
# 如果行或列到达img的边界,则向前取整
if row_near == img.shape[0] or col_near == img.shape[1]:
row_near -= 1
col_near -= 1
# 将最近的像素赋值给img_nearest
img_nearest[i][j] = img[row_near][col_near]
# 返回最近映射后的图像
return img_nearest
def Bilinear(img, height, width, channels):
# 生成一个用于存储bilinear插值结果的零矩阵
img_bilinear = np.zeros(shape=(height, width, channels), dtype=np.uint8)
# 对矩阵的每一个元素进行插值计算
for i in range(0, height):
for j in range(0, width):
# 计算当前元素所在的行和列的相对位置
row = (i / height) * img.shape[0]
col = (j / width) * img.shape[1]
row_int = int(row)
col_int = int(col)
# 计算当前元素所在点的权重
u = row - row_int
v = col - col_int
# 判断当前元素是否越界,若是则调整相对位置
if row_int == img.shape[0] - 1 or col_int == img.shape[1] - 1:
row_int -= 1
col_int -= 1
# 根据权重进行插值计算
img_bilinear[i][j] = (1 - u) * (1 - v) * img[row_int][col_int] + (1 - u) * v * img[row_int][col_int + 1] + u * (1 - v) * img[row_int + 1][col_int] + u * v * img[row_int + 1][col_int + 1]
# 返回bilinear插值结果
return img_bilinear后续在实现图像放缩时导入该函数即可,图像放缩代码如下:
python">import cv2
import matplotlib.pyplot as plt
from Nearest_Bilinear import *
# 读取图像
img = cv2.imread(r"D:\Image\img1.jpg", cv2.IMREAD_COLOR)
# 获取图像的高度、宽度和通道数
height, width, channels = img.shape
print(height, width, channels)
# 对图像进行放大操作,增加200个像素的高度
img_nearest_amplify = Nearest(img, height + 200, width, channels)
# 对图像进行缩小操作,减少200个像素的高度
img_nearest_reduce = Nearest(img, height - 200, width, channels)
# 创建一个大小为10x10的图像窗口
plt.figure(figsize=(10, 10))
# 在第一个子图中显示原始图像
plt.subplot(1, 3, 1), plt.axis('on'), plt.title("origin")
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
# 在第二个子图中显示放大后的图像
plt.subplot(1, 3, 2), plt.axis('on'), plt.title("Nearest_amplify")
plt.imshow(cv2.cvtColor(img_nearest_amplify, cv2.COLOR_BGR2RGB))
# 在第三个子图中显示缩小后的图像
plt.subplot(1, 3, 3), plt.axis('on'), plt.title("Nearest_reduce")
plt.imshow(cv2.cvtColor(img_nearest_reduce, cv2.COLOR_BGR2RGB))
plt.tight_layout()
plt.show()
# 对图像进行放大操作,增加200个像素的高度
img_bilinear_amplify = Bilinear(img, height + 200, width, channels)
# 对图像进行缩小操作,减少200个像素的高度
img_bilinear_reduce = Bilinear(img, height - 200, width, channels)
# 创建一个大小为10x10的图像窗口
plt.figure(figsize=(10, 10))
# 在第一个子图中显示原始图像
plt.subplot(1, 3, 1), plt.axis('on'), plt.title("origin")
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
# 在第二个子图中显示放大后的图像
plt.subplot(1, 3, 2), plt.axis('on'), plt.title("Bilinear_amplify")
plt.imshow(cv2.cvtColor(img_bilinear_amplify, cv2.COLOR_BGR2RGB))
# 在第三个子图中显示缩小后的图像
plt.subplot(1, 3, 3), plt.axis('on'), plt.title("Bilinear_reduce")
plt.imshow(cv2.cvtColor(img_bilinear_reduce, cv2.COLOR_BGR2RGB))
plt.tight_layout()
plt.show()
# 保存图像
retval = cv2.imwrite(r"D:\Image\image_lab2\img_nearest_amplify.jpg", img_nearest_amplify)
retval = cv2.imwrite(r"D:\Image\image_lab2\img_nearest_reduce.jpg", img_nearest_reduce)
retval = cv2.imwrite(r"D:\Image\image_lab2\img_bilinear_amplify.jpg", img_bilinear_amplify)
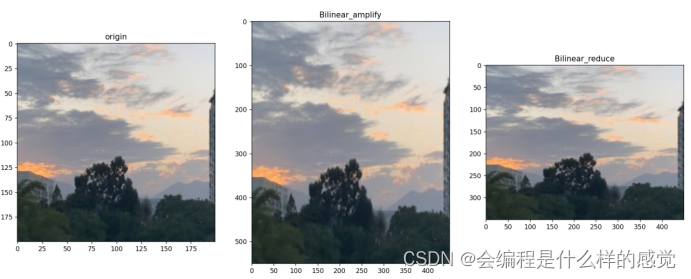
retval = cv2.imwrite(r"D:\Image\image_lab2\img_bilinear_reduce.jpg", img_bilinear_reduce)代码运行结果如下:
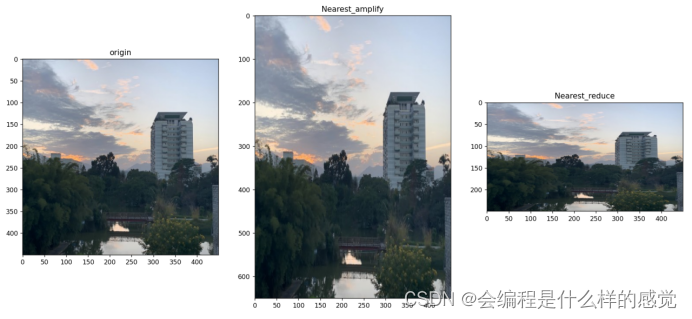

基于最近邻插值的视频缩放代码:
python">import cv2
import os
from Nearest_Bilinear import *
video_path = r"D:\Image\image_lab2\video_img"
# 获取视频文件夹中的所有文件
img_files = os.listdir(video_path)
# 统计图片文件数量
img_count = len(img_files)
# 设定视频编解码器
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
# 设定图片大小放大后的目标尺寸
img_size_amplify = (1280, 1280)
# 设定图片大小缩小后的目标尺寸
img_size_reduce = (720, 720)
# 视频保存路径(放大版本)
video_save_amplify = r"D:\Image\image_lab2\video_amplify_Nearest.mp4"
# 视频保存路径(缩小版本)
video_save_reduce = r"D:\Image\image_lab2\video_reduce_Nearest.mp4"
# 创建放大版本的视频写入对象
video_writer_amplify = cv2.VideoWriter(video_save_amplify, fourcc, 60, img_size_amplify)
# 创建缩小版本的视频写入对象
video_writer_reduce = cv2.VideoWriter(video_save_reduce, fourcc, 60, img_size_reduce)
print("视频放大及缩小开始")
for i in range(0, img_count):
# 设定图片文件路径
img_path = video_path + "/" + str(i) + ".jpg"
# 读取图片
img = cv2.imread(img_path, cv2.IMREAD_COLOR)
# 若读取失败则跳过本次循环
if img is None:
continue
# 图片放大
img_amplify = Nearest(img, img_size_amplify[0], img_size_amplify[1], 3)
# 图片缩小
img_reduce = Nearest(img, img_size_reduce[0], img_size_reduce[1], 3)
# 将放大后的图片写入放大版本的视频
video_writer_amplify.write(img_amplify)
# 将缩小后的图片写入缩小版本的视频
video_writer_reduce.write(img_reduce)
print(f"第{i}张图片合成完成")
print("视频放大及缩小完成")基于双线性插值的视频放缩代码:
python">import cv2
import os
from Nearest_Bilinear import *
video_path = r"D:\Image\image_lab2\video_img"
# 获取视频文件夹中的所有文件
img_files = os.listdir(video_path)
# 统计图片文件数量
img_count = len(img_files)
# 设定视频编解码器
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
# 设定图片大小放大后的目标尺寸
img_size_amplify = (1280, 1280)
# 设定图片大小缩小后的目标尺寸
img_size_reduce = (720, 720)
# 视频保存路径(放大版本)
video_save_amplify = r"D:\Image\image_lab2\video_amplify_Bilinear.mp4"
# 视频保存路径(缩小版本)
video_save_reduce = r"D:\Image\image_lab2\video_reduce_Bilinear.mp4"
# 创建放大版本的视频写入对象
video_writer_amplify = cv2.VideoWriter(video_save_amplify, fourcc, 60, img_size_amplify)
# 创建缩小版本的视频写入对象
video_writer_reduce = cv2.VideoWriter(video_save_reduce, fourcc, 60, img_size_reduce)
print("视频放大及缩小开始")
for i in range(0, img_count):
# 设定图片文件路径
img_path = video_path + "/" + str(i) + ".jpg"
# 读取图片
img = cv2.imread(img_path, cv2.IMREAD_COLOR)
# 若读取失败则跳过本次循环
if img is None:
continue
# 图片放大
img_amplify = Bilinear(img, img_size_amplify[0], img_size_amplify[1], 3)
# 图片缩小
img_reduce = Bilinear(img, img_size_reduce[0], img_size_reduce[1], 3)
# 将放大后的图片写入放大版本的视频
video_writer_amplify.write(img_amplify)
# 将缩小后的图片写入缩小版本的视频
video_writer_reduce.write(img_reduce)
print(f"第{i}张图片合成完成")
print("视频放大及缩小完成")(2)基于OpenCV的局部图像和视频缩放
局部图像的缩放代码如下:
python">import cv2
import matplotlib.pyplot as plt
# 读取原始图像
img_origin = cv2.imread(r"D:\Image\img1.jpg", cv2.IMREAD_COLOR)
# 获取图像的高度和宽度
height, width = img_origin.shape[:2]
# 定义图像的一部分的坐标范围
y1, y2 = 100, 300
x1, x2 = 100, 300
# 获取图像的一部分
img_part = img_origin[y1:y2, x1:x2]
# 放大图像
img_amplify = cv2.resize(img_part, None, fx=1.25, fy=1.0, interpolation=cv2.INTER_NEAREST)
# 缩小图像
img_reduce = cv2.resize(img_part, None, fx=0.75, fy=1.0, interpolation=cv2.INTER_LINEAR)
# 创建绘图窗口
plt.figure(figsize=(10, 10))
# 绘制图像
plt.subplot(2, 2, 1), plt.axis('on'), plt.title("origin")
plt.imshow(cv2.cvtColor(img_origin, cv2.COLOR_BGR2RGB))
plt.subplot(2, 2, 2), plt.axis('on'), plt.title("part")
plt.imshow(cv2.cvtColor(img_part, cv2.COLOR_BGR2RGB))
plt.subplot(2, 2, 3), plt.axis('on'), plt.title("amplify: fx = 1.25, fy = 1.0")
plt.imshow(cv2.cvtColor(img_amplify, cv2.COLOR_BGR2RGB))
plt.subplot(2, 2, 4), plt.axis('on'), plt.title("reduce: fx = 0.75, fy = 1.0")
plt.imshow(cv2.cvtColor(img_reduce, cv2.COLOR_BGR2RGB))
# 调整子图布局
plt.tight_layout()
# 显示图形
plt.show()
# 保存图像
retval = cv2.imwrite(r"D:\Image\image_lab2\img_part.jpg", img_part)
retval = cv2.imwrite(r"D:\Image\image_lab2\img_amplify_part.jpg", img_amplify)
retval = cv2.imwrite(r"D:\Image\image_lab2\img_reduce_part.jpg", img_reduce)
局部视频的缩放代码如下:
python">import cv2
import os
video_path = r"D:\Image\image_lab2\video_img"
# 获取视频文件夹中的所有文件
img_files = os.listdir(video_path)
# 统计图片文件数量
img_count = len(img_files)
# 设定视频编解码器
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
# 设定图片大小放大后的目标尺寸
img_size_amplify = (720, 720)
# 设定图片大小缩小后的目标尺寸
img_size_reduce = (250, 250)
# 视频保存路径(放大版本)
video_save_amplify = r"D:\Image\image_lab2\video_amplify_part.mp4"
# 视频保存路径(缩小版本)
video_save_reduce = r"D:\Image\image_lab2\video_reduce_part.mp4"
# 创建放大版本的视频写入对象
video_writer_amplify = cv2.VideoWriter(video_save_amplify, fourcc, 60, img_size_amplify)
# 创建缩小版本的视频写入对象
video_writer_reduce = cv2.VideoWriter(video_save_reduce, fourcc, 60, img_size_reduce)
print("视频放大及缩小开始")
for i in range(0, img_count):
# 设定图片文件路径
img_path = video_path + "/" + str(i) + ".jpg"
# 读取图片
img = cv2.imread(img_path, cv2.IMREAD_COLOR)
img = img[100:500, 100:500]
# 若读取失败则跳过本次循环
if img is None:
continue
# 图片放大
img_amplify = cv2.resize(img, img_size_amplify)
# 图片缩小
img_reduce = cv2.resize(img, img_size_reduce)
# 将放大后的图片写入放大版本的视频
video_writer_amplify.write(img_amplify)
# 将缩小后的图片写入缩小版本的视频
video_writer_reduce.write(img_reduce)
print(f"第{i}张图片合成完成")
print("视频放大及缩小完成")基于最近邻插值和双线性插值的局部图像和视频缩放:
局部图像的缩放代码如下:
python">import cv2
import matplotlib.pyplot as plt
from Nearest_Bilinear import *
# 读取图像
img = cv2.imread(r"D:\Image\img1.jpg", cv2.IMREAD_COLOR)
# 获取图像的高度、宽度和通道数
height, width, channels = img.shape
# 定义图像的一部分的坐标范围
y1, y2 = 100, 300
x1, x2 = 100, 300
# 获取图像的一部分
img_part = img[y1:y2, x1:x2]
# 对图像进行放大操作,增加100个像素的高度
img_nearest_amplify_part = Nearest(img_part, height + 100, width, channels)
# 对图像进行缩小操作,减少100个像素的高度
img_nearest_reduce_part = Nearest(img_part, height - 100, width, channels)
# 创建一个大小为10x10的图像窗口
plt.figure(figsize=(10, 10))
# 在第一个子图中显示原始图像
plt.subplot(1, 3, 1), plt.axis('on'), plt.title("origin")
plt.imshow(cv2.cvtColor(img_part, cv2.COLOR_BGR2RGB))
# 在第二个子图中显示放大后的图像
plt.subplot(1, 3, 2), plt.axis('on'), plt.title("Nearest_amplify")
plt.imshow(cv2.cvtColor(img_nearest_amplify_part, cv2.COLOR_BGR2RGB))
# 在第三个子图中显示缩小后的图像
plt.subplot(1, 3, 3), plt.axis('on'), plt.title("Nearest_reduce")
plt.imshow(cv2.cvtColor(img_nearest_reduce_part, cv2.COLOR_BGR2RGB))
plt.tight_layout()
plt.show()
# 对图像进行放大操作,增加100个像素的高度
img_bilinear_amplify_part = Bilinear(img_part, height + 100, width, channels)
# 对图像进行缩小操作,减少100个像素的高度
img_bilinear_reduce_part = Bilinear(img_part, height - 100, width, channels)
# 创建一个大小为10x10的图像窗口
plt.figure(figsize=(10, 10))
# 在第一个子图中显示原始图像
plt.subplot(1, 3, 1), plt.axis('on'), plt.title("origin")
plt.imshow(cv2.cvtColor(img_part, cv2.COLOR_BGR2RGB))
# 在第二个子图中显示放大后的图像
plt.subplot(1, 3, 2), plt.axis('on'), plt.title("Bilinear_amplify")
plt.imshow(cv2.cvtColor(img_bilinear_amplify_part, cv2.COLOR_BGR2RGB))
# 在第三个子图中显示缩小后的图像
plt.subplot(1, 3, 3), plt.axis('on'), plt.title("Bilinear_reduce")
plt.imshow(cv2.cvtColor(img_bilinear_reduce_part, cv2.COLOR_BGR2RGB))
plt.tight_layout()
plt.show()
# 保存图像
retval = cv2.imwrite(r"D:\Image\image_lab2\img_nearest_amplify_part.jpg", img_nearest_amplify_part)
retval = cv2.imwrite(r"D:\Image\image_lab2\img_nearest_reduce_part.jpg", img_nearest_reduce_part)
retval = cv2.imwrite(r"D:\Image\image_lab2\img_bilinear_amplify_part.jpg", img_bilinear_amplify_part)
retval = cv2.imwrite(r"D:\Image\image_lab2\img_bilinear_reduce_part.jpg", img_bilinear_reduce_part)
基于最近邻插值的局部视频缩放代码:
python">import cv2
import os
from Nearest_Bilinear import *
video_path = r"D:\Image\image_lab2\video_img"
# 获取视频文件夹中的所有文件
img_files = os.listdir(video_path)
# 统计图片文件数量
img_count = len(img_files)
# 设定视频编解码器
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
# 设定图片大小放大后的目标尺寸
img_size_amplify = (720, 720)
# 设定图片大小缩小后的目标尺寸
img_size_reduce = (250, 250)
# 视频保存路径(放大版本)
video_save_amplify = r"D:\Image\image_lab2\video_amplify_Nearest_part.mp4"
# 视频保存路径(缩小版本)
video_save_reduce = r"D:\Image\image_lab2\video_reduce_Nearest_part.mp4"
# 创建放大版本的视频写入对象
video_writer_amplify = cv2.VideoWriter(video_save_amplify, fourcc, 60, img_size_amplify)
# 创建缩小版本的视频写入对象
video_writer_reduce = cv2.VideoWriter(video_save_reduce, fourcc, 60, img_size_reduce)
print("视频放大及缩小开始")
for i in range(0, img_count):
# 设定图片文件路径
img_path = video_path + "/" + str(i) + ".jpg"
# 读取图片
img = cv2.imread(img_path, cv2.IMREAD_COLOR)
img = img[100:500, 100:500]
# 若读取失败则跳过本次循环
if img is None:
continue
# 图片放大
img_amplify = Nearest(img, img_size_amplify[0], img_size_amplify[1], 3)
# 图片缩小
img_reduce = Nearest(img, img_size_reduce[0], img_size_reduce[1], 3)
# 将放大后的图片写入放大版本的视频
video_writer_amplify.write(img_amplify)
# 将缩小后的图片写入缩小版本的视频
video_writer_reduce.write(img_reduce)
print(f"第{i}张图片合成完成")
print("视频放大及缩小完成")基于双线性插值的局部视频缩放代码如下:
python">import cv2
import os
from Nearest_Bilinear import *
video_path = r"D:\Image\image_lab2\video_img"
# 获取视频文件夹中的所有文件
img_files = os.listdir(video_path)
# 统计图片文件数量
img_count = len(img_files)
# 设定视频编解码器
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
# 设定图片大小放大后的目标尺寸
img_size_amplify = (720, 720)
# 设定图片大小缩小后的目标尺寸
img_size_reduce = (250, 250)
# 视频保存路径(放大版本)
video_save_amplify = r"D:\Image\image_lab2\video_amplify_Bilinear_part.mp4"
# 视频保存路径(缩小版本)
video_save_reduce = r"D:\Image\image_lab2\video_reduce_Bilinear_part.mp4"
# 创建放大版本的视频写入对象
video_writer_amplify = cv2.VideoWriter(video_save_amplify, fourcc, 60, img_size_amplify)
# 创建缩小版本的视频写入对象
video_writer_reduce = cv2.VideoWriter(video_save_reduce, fourcc, 60, img_size_reduce)
print("视频放大及缩小开始")
for i in range(0, img_count):
# 设定图片文件路径
img_path = video_path + "/" + str(i) + ".jpg"
# 读取图片
img = cv2.imread(img_path, cv2.IMREAD_COLOR)
img = img[100:500, 100:500]
# 若读取失败则跳过本次循环
if img is None:
continue
# 图片放大
img_amplify = Bilinear(img, img_size_amplify[0], img_size_amplify[1], 3)
# 图片缩小
img_reduce = Bilinear(img, img_size_reduce[0], img_size_reduce[1], 3)
# 将放大后的图片写入放大版本的视频
video_writer_amplify.write(img_amplify)
# 将缩小后的图片写入缩小版本的视频
video_writer_reduce.write(img_reduce)
print(f"第{i}张图片合成完成")
print("视频放大及缩小完成")都看到最后了,不点个赞吗?



