1、前言
Picsart人工智能研究所、德克萨斯大学和SHI实验室的研究人员联合推出了StreamingT2V视频模型。通过文本就能直接生成2分钟、1分钟等不同时间,动作一致、连贯、没有卡顿的高质量视频。
虽然StreamingT2V在视频质量、多元化等还无法与Sora媲美,但在高速运动方面非常优秀,这为开发长视频模型提供了技术思路。
研究人员表示,理论上,StreamingT2V可以无限扩展视频的长度,并正在准备开源该视频模型。
论文地址:https://arxiv.org/abs/2403.14773
github地址:https://github.com/Picsart-AI-Research/StreamingT2V(即将开源)
2、介绍
传统视频模型一直受训练数据、算法等困扰,最多只能生成10秒视频。Sora的出现将文生视频领域带向了一个全新的高度,突破了诸多技术瓶颈,仅通过文本就能生成最多1分钟的视频。
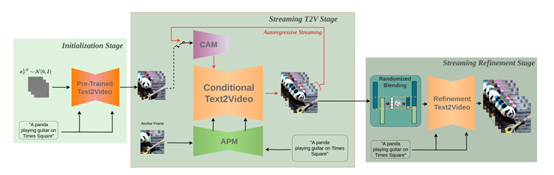
而StreamingT2V采用了创新的自回归技术框架,通过条件注意力、外观保持和随机混合三大模块,极大的延长了视频的时间,同时保证动作的连贯性。
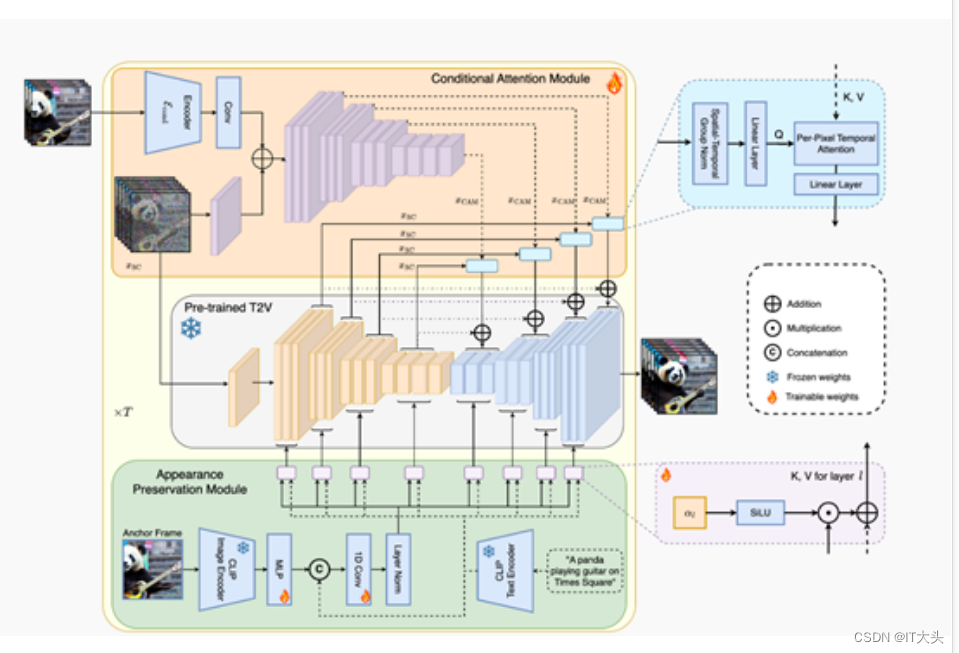
简单来说,StreamingT2V使用了一种“击鼓传花”的方法,每一个模块通过提取前一个视频块中的表示特征,来保证动作一致性、文本语义还原、视频完整性等。
2.1、条件注意力模块
条件注意力模块是一种“短期记忆”,通过注意力机制从前一个视频块中提取特征,并将其注入到当前视频块的生成中,实现了流畅自然的块间过渡,同时保留了高速运动特征。
先使用图像编码器对前一个视频块的最后几帧(例如20帧)进行逐帧编码,得到相应的特征表示,并将这些特征送入一个浅层编码器网络(初始化自主模型的编码器权重)进行进一步编码。
然后将提取到的特征表示注入到StreamingT2V的UNet的每个长程跳跃连接处,从而借助前一视频块的内容信息来生成新的视频帧,但不会受到先前结构、形状的影响。
2.2、外观保持模块
为了保证生成视频全局场景、外观的一致性,StreamingT2V使用了外观保持这种“长期记忆”方法。
外观保持从初始图像(锚定帧)中提取高级场景和对象特征,并将这些特征用于所有视频块的生成流程。这样做可以帮助在自回归过程中,保持对象和场景特征的连续性。

此外,现有方法通常只针对前一个视频块的最后一帧进行条件生成,忽视了自回归过程中的长期依赖性。通过使用外观保持,可以使用初始图像中的全局信息,从而更好地捕捉到自回归过程中的长期依赖性。
2.3、随机混合模块
前两个模块保证了StreamingT2V生成的视频大框架,但是在分辨率、质量方面还有欠缺,而随机混合模块主要用来增强视频的分辨率。
如果直接增强质量会耗费大量AI算力、时间,所以,随机混合采用了自回归增强的方法。
首先,研究人员将低分辨率视频划分为多个长度为24帧的视频块,这些块之间是有重叠的。然后,利用一个高分辨率的视频模型,对每一个视频块进行增强,得到对应的高分辨率视频块。

例如,有两个重叠的视频块A和B,重叠部分包含20帧。对于重叠部分的每一帧,随机混合模块会从A块和B块中各取出一帧,然后对这两帧进行加权平均,生成一个新的混合帧。通过这种方式,重叠部分的每一帧都是A块和B块对应帧的随机混合。
而对于不重叠的部分,随机混合模块则直接保留原始视频块中的帧。经过随机混合后的视频块就可以输入到高分辨率模型中进行增强。
研究人员指出,如果让相邻的两个视频块直接共享完全相同的重叠帧,会导致视频在过渡处出现不自然的冻结和重复效果。而随机混合模块通过生成新的混合帧,很好地规避了这个难题,使得块与块之间的过渡更加平滑自然。
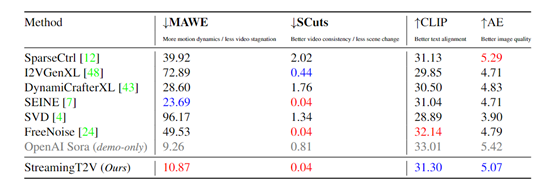
实验数据显示, StreamingT2V生成的1分钟、2分钟长视频,不仅保持了高分辨率和清晰画质,整体的时间连贯性也得到了很大提升。视频中的物体运动姿态丰富,场景和物体随时间的演变更加自然流畅,没有突兀的断层或冻结情况出现。