前言
生成NxN的像素矩阵是对图像进行各类滤波操作的基本前提,本文介绍一种通过bram生成3x3矩阵的方法。
程序
生成bram核
因为本文介绍的是基于bram生成的3x3像素矩阵,所以要先生成两个bram核,用于缓存前两行图像数据
在 IP catalog中选择Block Memory Generator
配置如下
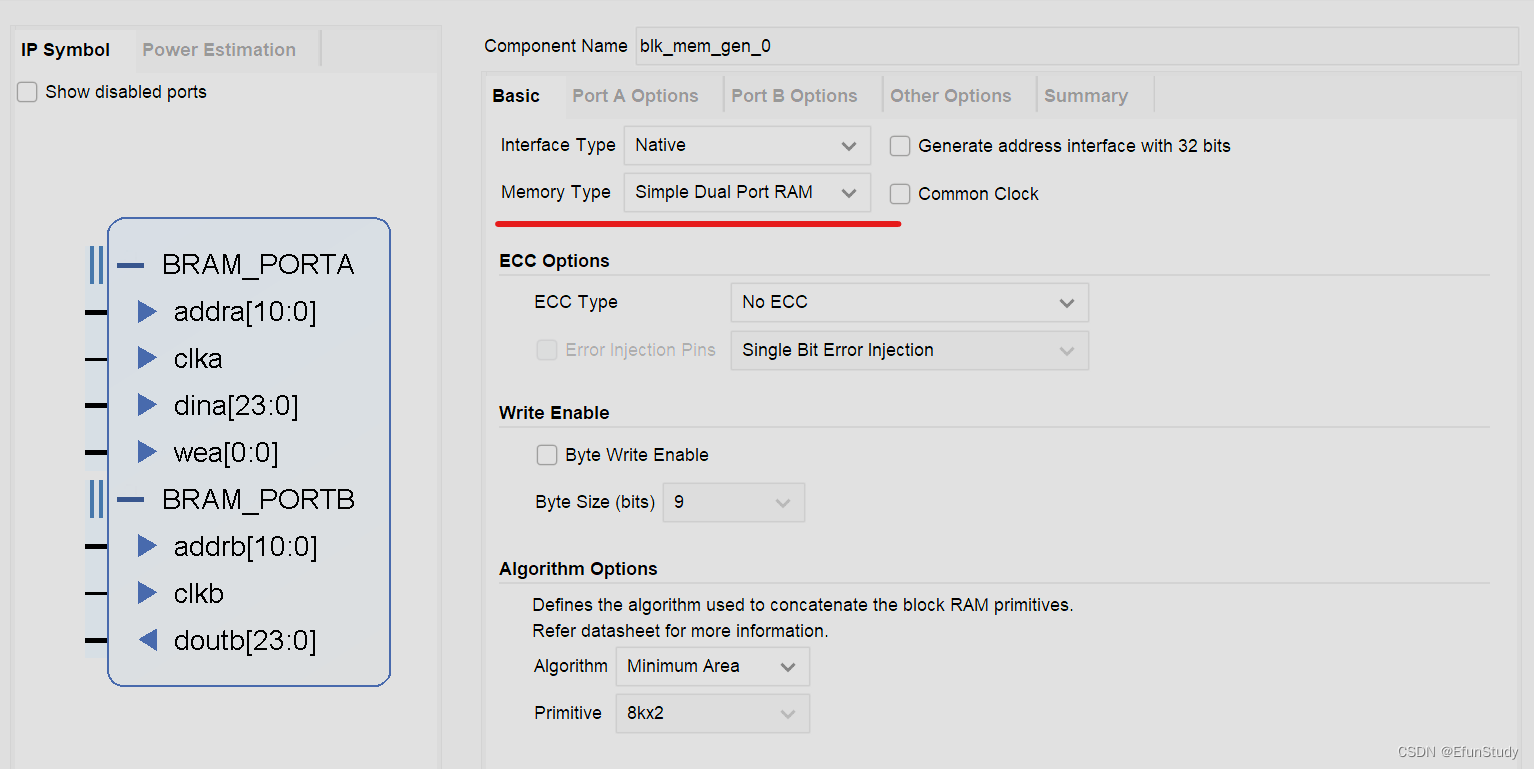
注意这里选择simple dual port RAM,即伪双端口,一个端口只能写,一个端口只能读
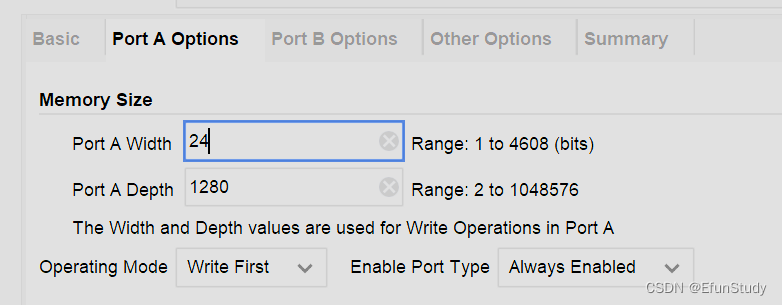
端口A用于写入数据,注意数据的位宽要与图像位深相同,彩色通常为24位,灰度图为8位,数据深度为一行像素的长度,operating选择写优先,enable port type选择始终使能

端口B用于读取数据,这里要注意下面的primitives output register要勾选上,勾选该选项后,数据的输出会延迟一个时钟周期,用于对齐数据。
HDMI时序生成模块
这里也用到了HDMI时序生成模块,具体作用和前面文章讲的一样,一是可以做到通过同步信号简化对图像数据的管理,二是可以让测试的数据处理模块更方便的适配用HDMI显示的图像处理工程。
具体代码如下
module hdmi_tim_gen(
input clk ,
input rst_n ,
input [23:0] data_in ,
output hdmi_hs , //行同步信号
output hdmi_vs , //场同步信号
output hdmi_de , //数据使能
output [23:0] hdmi_data , //RGB888颜色数据
output reg data_req
);
//1280*720 分辨率时序参数
parameter H_SYNC = 11'd40; //行同步
parameter H_BACK = 11'd220; //行显示后沿
parameter H_DISP = 11'd1280; //行有效数据
parameter H_FRONT = 11'd110; //行显示前沿
parameter H_TOTAL = 11'd1650; //行扫描周期
parameter V_SYNC = 11'd5; //场同步
parameter V_BACK = 11'd20; //场显示后沿
parameter V_DISP = 11'd720; //场有效数据
parameter V_FRONT = 11'd5; //场显示前沿
parameter V_TOTAL = 11'd750; //场扫描周期
//reg define
reg [11:0] cnt_h;
reg [11:0] cnt_v;
reg [10:0] pixel_xpos;
reg [10:0] pixel_ypos;
assign hdmi_de = data_req;
assign hdmi_hs = ( cnt_h < H_SYNC ) ? 1'b0 : 1'b1; //行同步信号赋值
assign hdmi_vs = ( cnt_v < V_SYNC ) ? 1'b0 : 1'b1; //场同步信号赋值
//RGB888数据输出
assign hdmi_data = hdmi_de ? data_in : 24'd0;
//请求像素点颜色数据输入
always @(posedge clk or negedge rst_n) begin
if(!rst_n)
data_req <= 1'b0;
else if(((cnt_h >= H_SYNC + H_BACK - 2'd2) && (cnt_h < H_SYNC + H_BACK + H_DISP - 2'd2))
&& ((cnt_v >= V_SYNC + V_BACK) && (cnt_v < V_SYNC + V_BACK+V_DISP)))
data_req <= 1'b1;
else
data_req <= 1'b0;
end
//像素点x坐标
always@ (posedge clk or negedge rst_n) begin
if(!rst_n)
pixel_xpos <= 11'd0;
else if(data_req)
pixel_xpos <= cnt_h + 2'd2 - H_SYNC - H_BACK ;
else
pixel_xpos <= 11'd0;
end
//像素点y坐标
always@ (posedge clk or negedge rst_n) begin
if(!rst_n)
pixel_ypos <= 11'd0;
else if((cnt_v >= (V_SYNC + V_BACK)) && (cnt_v < (V_SYNC + V_BACK + V_DISP)))
pixel_ypos <= cnt_v + 1'b1 - (V_SYNC + V_BACK) ;
else
pixel_ypos <= 11'd0;
end
//行计数器对像素时钟计数
always @(posedge clk or negedge rst_n) begin
if (!rst_n)
cnt_h <= 11'd0;
else begin
if(cnt_h < H_TOTAL - 1'b1)
cnt_h <= cnt_h + 1'b1;
else
cnt_h <= 11'd0;
end
end
//场计数器对行计数
always @(posedge clk or negedge rst_n) begin
if (!rst_n)
cnt_v <= 11'd0;
else if(cnt_h == H_TOTAL - 1'b1) begin
if(cnt_v < V_TOTAL - 1'b1)
cnt_v <= cnt_v + 1'b1;
else
cnt_v <= 11'd0;
end
end
endmodule生成3x3像素矩阵的顶层模块
module kernel_3x3_gen
(
input clk,
input rst_n,
//准备要进行处理的图像数据
input vs_i,
input de_i,
input [23:0] data_i,
//矩阵化后的图像数据和控制信号
output vs_o,
output de_o,
output reg [23:0] mat11,
output reg [23:0] mat12,
output reg [23:0] mat13,
output reg [23:0] mat21,
output reg [23:0] mat22,
output reg [23:0] mat23,
output reg [23:0] mat31,
output reg [23:0] mat32,
output reg [23:0] mat33
);
//wire define
wire [23:0] row1_data; //第一行数据
wire [23:0] row2_data; //第二行数据
wire de_i_en ;
//reg define
reg [23:0] row3_data; //第三行数据,即当前正在接受的数据
reg [23:0] row3_data_d0;
reg [23:0] row3_data_d1;
reg [23:0] row2_data_d0;
reg [1:0] vs_i_d;
reg [1:0] de_i_d;
assign de_i_en = de_i_d[0] ;
assign vs_o = vs_i_d[1];
assign de_o = de_i_d[1] ;
//当前数据放在第3行
always@(posedge clk or negedge rst_n) begin
if(!rst_n)
row3_data <= 0;
else begin
if(de_i)
row3_data <= data_i ;
else
row3_data <= row3_data ;
end
end
//用于存储列数据的RAM
line_shift u_line_shift
(
.clk (clk),
.de_i (de_i),
.data_i (data_i), //当前行的数据
.data1_o (row2_data), //前一行的数据
.data2_o (row1_data) //前前一行的数据
);
//将同步信号延迟两拍,用于同步化处理
always@(posedge clk or negedge rst_n) begin
if(!rst_n) begin
vs_i_d <= 0;
de_i_d <= 0;
end
else begin
vs_i_d <= { vs_i_d[0], vs_i };
de_i_d <= { de_i_d[0], de_i };
end
end
always @(posedge clk or negedge rst_n)begin
if(!rst_n)begin
row3_data_d1 <= 0;
row3_data_d0 <= 0;
row2_data_d0 <= 0;
end
else begin
row3_data_d0 <= row3_data;
row3_data_d1 <= row3_data_d0;
row2_data_d0 <= row2_data;
end
end
//在同步处理后的控制信号下,输出图像矩阵
always@(posedge clk or negedge rst_n) begin
if(!rst_n) begin
{mat11, mat12, mat13} <= 0;
{mat21, mat22, mat23} <= 0;
{mat31, mat32, mat33} <= 0;
end
else if(de_i_en) begin
{mat11, mat12, mat13} <= {mat12, mat13, row1_data};
{mat21, mat22, mat23} <= {mat22, mat23, row2_data_d0};
{mat31, mat32, mat33} <= {mat32, mat33, row3_data_d1};
end
else begin
{mat11, mat12, mat13} <= 0;
{mat21, mat22, mat23} <= 0;
{mat31, mat32, mat33} <= 0;
end
end
endmodule
行移位模块
module line_shift(
input clk,
input de_i,
input [23:0] data_i, //当前行的数据
output [23:0] data1_o, //前一行的数据
output [23:0] data2_o //前前一行的数据
);
//reg define
reg de_i_d0;
reg de_i_d1;
reg de_i_d2;
reg [10:0] ram_rd_addr;
reg [10:0] ram_rd_addr_d0;
reg [10:0] ram_rd_addr_d1;
reg [23:0] data_i_d0;
reg [23:0] data_i_d1;
reg [23:0] data_i_d2;
reg [23:0] data1_o_d0;
//在数据到来时,RAM的读地址累加
always@(posedge clk)begin
if(de_i)
ram_rd_addr <= ram_rd_addr + 1 ;
else
ram_rd_addr <= 0 ;
end
//将数据使能延迟两拍
always@(posedge clk) begin
de_i_d0 <= de_i;
de_i_d1 <= de_i_d0;
de_i_d2 <= de_i_d1;
end
//将RAM地址延迟2拍
always@(posedge clk ) begin
ram_rd_addr_d0 <= ram_rd_addr;
ram_rd_addr_d1 <= ram_rd_addr_d0;
end
//输入数据延迟3拍送入RAM
always@(posedge clk)begin
data_i_d0 <= data_i;
data_i_d1 <= data_i_d0;
data_i_d2 <= data_i_d1;
end
//用于存储前一行图像的RAM
blk_mem_gen_0 u_ram_1024x8_0(
.clka (clk),
.wea (de_i_d2),
.addra (ram_rd_addr_d1), //在延迟的第三个时钟周期,当前行的数据写入RAM0
.dina (data_i_d2),
.clkb (clk),
.addrb (ram_rd_addr),
.doutb (data1_o) //延迟一个时钟周期,输出RAM0中前一行图像的数据
);
//寄存前一行图像的数据
always@(posedge clk)begin
data1_o_d0 <= data1_o;
end
//用于存储前前一行图像的RAM
blk_mem_gen_0 u_ram_1024x8_1(
.clka (clk),
.wea (de_i_d1),
.addra (ram_rd_addr_d0),
.dina (data1_o_d0), //在延迟的第二个时钟周期,将前一行图像的数据写入RAM1
.clkb (clk),
.addrb (ram_rd_addr),
.doutb (data2_o) //延迟一个时钟周期,输出RAM1中前前一行图像的数据
);
endmodule
仿真模块
`timescale 1ns/1ns
module pic_tb();
reg clk,rst_n ;
reg [23:0] data_in ;
wire hdmi_hs,hdmi_vs,hdmi_de ;
wire [23:0] hdmi_data ;
wire data_req ;
reg vs_i,de_i ;
wire vs_o,de_o ;
wire [23:0] mat11, mat12, mat13 ;
wire [23:0] mat21, mat22, mat23 ;
wire [23:0] mat31, mat32, mat33 ;
//延迟1clk,与data同步,hdmi时序中,data比de延迟了一个时钟周期
always @(posedge clk)begin
vs_i <= hdmi_vs;
de_i <= hdmi_de;
end
initial begin
clk = 1;
rst_n = 0;
#20 rst_n = 1;
end
always #10 clk = ~clk;
reg [23:0] img[0:1280*720-1];
reg [31:0] addr;
initial begin
$readmemh("D:/pic/img2txt.txt",img);
end
always @(posedge clk or negedge rst_n)begin
if(!rst_n)begin
addr <= 0 ;
data_in <= 0 ;
end
else if(data_req) begin
data_in <= img[addr];
addr <= addr + 1;
if(addr == (1280*720-1))
addr <= 0;
end
end
hdmi_tim_gen u_hdmi_tim_gen(
.clk (clk),
.rst_n (rst_n),
//input
.data_in (data_in),
//output
.hdmi_hs (hdmi_hs),
.hdmi_vs (hdmi_vs),
.hdmi_de (hdmi_de),
.hdmi_data (hdmi_data),
.data_req (data_req)
);
kernel_3x3_gen u_kernel_3x3_gen(
.clk (clk),
.rst_n (rst_n),
//预处理灰度数据
.vs_i (vs_i),
.de_i (de_i),
.data_i (hdmi_data),
//输出3x3矩阵
.vs_o (vs_o),
.de_o (de_o),
.mat11 (mat11),
.mat12 (mat12),
.mat13 (mat13),
.mat21 (mat21),
.mat22 (mat22),
.mat23 (mat23),
.mat31 (mat31),
.mat32 (mat32),
.mat33 (mat33)
);
endmodule整体架构

仿真结果
截取部分数据结果

mat31、mat32、mat33是第一行数据(最先输入的那一行),mat11、mat12、mat13是第三行数据(最后输入的那一行),可以看见数据的移位满足像素矩阵的要求。



![[尚硅谷flink] 水位线](https://img-blog.csdnimg.cn/img_convert/c7b2b95049d62f67eb73906a0782c98b.png)